
作者: 徐桂林
大概两个月之前,我曾经写过一篇关于DevOps如何在团队落地的文章《 火热的DevOps如何在你的团队落地 》。在这篇文章中提到DevOps落地的抓手是持续交付,并提供了一组衡量团队应用交付能力的指标。今天,这篇文章则沿着这个路径继续深入讨论,希望能够给团队领导者在落实DevOps实践时提供一个参照坐标系,对大家定位问题,明确方向有一丁点帮助。
为什么要尝试DevOps?
或许你希望了解团队为什么需要尝试DevOps实践,或者DevOps实践能够给团队及企业带来什么样的投入产出。由于这篇文章的主题不是讨论尝试DevOps的必要性,所以这里就不再展开叙述,而只引用Puppet Labs 2014 DevOps调查报告的部分调查结果做一佐证。如果希望更深入了解这个主题,建议全面阅读这份调查报告。
Puppet Labs 2014 DevOps用具体调查数据揭示了组织绩效、IT服务绩效与DevOps实践之间的关系。其中的核心观点如下:
- 拥有强IT服务绩效的企业通常会双倍超过其市场及盈利目标;
- 企业的IT服务绩效和DevOps推崇的普遍实践(如持续交付等)有非常明显的正相关。例如,调查发现强IT服务绩效的团队比较差IT服务绩效团队的部署频率要快30倍,变更失败率要低50%。
回到我们的现状
在探讨如何定位团队DevOps实践能力前,让我们回到现实,看看很多企业目前的软件生产流程。下图是我们在和很多企业沟通后总结出来的一个典型的软件生产流程:
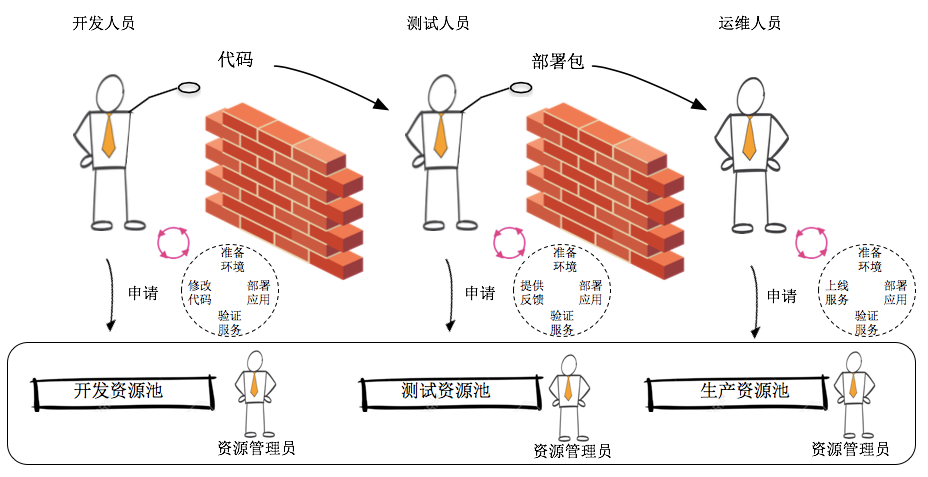
在这个软件生产方式中,普遍影响整个流程产出的因素有如下两点:
- 资源获取和环境准备效率低。无论是开发、测试还是生产环境,工程人员都必须走非常冗长的流程才能够获取相应的资源(计算、存储和网络)。并且获取后的资源质量和环境准备情况还很难保障。资源初始化的工作非常繁琐并且容易出错。总结来说,团队内缺少标准化、自动化的自服务IT(self-IT)能力。
- 从代码到服务的通道不顺畅。如上图所示,尽管是在同一个组织内,为同一个软件或者服务产品工作,开发、测试和运维人员之间的“部门墙”仍然非常明显。开发人员不清楚最终的软件会如何部署和运行,测试人员不了解软件测试的重点和风险点在什么地方,运维人员不清楚软件架构的高可用设计是如何实现的。部门之间基本靠非常零碎、极易过时的文档或者口头沟通来交换信息。这直接导致从代码到最终服务上线的通道不顺畅,降低了软件交付的频率和质量。
非常不幸的是,上面两个工程上的问题常常没有在项目开始阶段就得到足够重视,反而被认为是“最简单”的事情。于是,项目开始阶段大家所有的精力都放在如需求分析、架构设计、测试用例设计等其他“更重要”的事情上。等到最后快上线时候,当大家开始所谓“最简单”事情的时发现困难重重,问题百出。最终要不就是上线失败,要不就是一堆临时方案凑合上线。而对于一个真正的DevOps团队则会在项目开始阶段就高度重视这两个问题,并以此为目标搭建好一系列的工具链和流程,然后在这个工具链和流程的保障下快速迭代需求、设计、实现以及测试运维方案等。
DevOps坐标系
在软件工程领域一个非常有效的理念就是“提前把最痛苦的事情频繁得做、反复得做,直到它变成一个不痛苦的事情”。在DevOps实践中,上面提到的两个“痛苦”的事情则恰恰构成了DevOps关键能力指标。一个优秀的DevOps能力团队能够让这两件“痛苦”的事情变成像“中午订个盒饭”一样常态化。在这个能力支撑下,团队才能高效实现产品迭代、快速响应市场变化,从而促进业务创新。
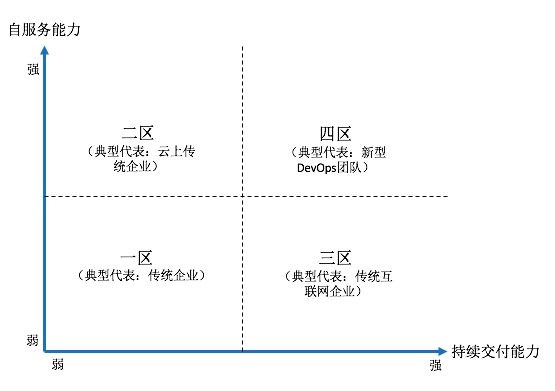
如果以上面两个指标(自服务能力与持续交付能力)建立一个DevOps能力坐标系,并以此衡量企业内DevOps能力会是一个非常有益的参照系统。下图描述这个能力坐标系及我们观察到的典型代表。
- 持续交付能力:描述团队应用交付的能力,其最主要的衡量标准包括“交付频率”和“交付成功率”。这个交付能力在不同行业、不同业务类型之间有一定差异,团队可以参照历史记录和同行数据做判断。
- 自服务能力:描述团队获取资源和环境的能力。由于云平台的快速普及,现在这个能力得到了非常大的提升。一般来说需要达到十五分钟交付一台部署好的主机、一个小时交付一个完整的集群环境才能算达到自服务IT的能力(注:这个交付过程是自助式的,无需他人常态化的参与其中)。
对照上面DevOps能力坐标系,不同企业的DevOps能力可能会落到不同区域,具体来说如下:
- 一区:这个区域以传统企业最为典型。这类企业基本处在最传统的软件研发流程中,以年(或者季度)为一次交付周期,且交付风险高。同时,企业内部的基础设施资源集中管理,工程人员获取一次资源的时间一般以天(或者周)为单位。
- 二区:这个区域最为典型的代表是云上传统企业。这类企业开始采用云基础设施,企业内工程人员得益于云平台资源自服务能力,获取资源的能力有较大提升,但是企业软件研发及交付能力仍然和原来一样,停留在非常低的频率,且交付失败率仍然很高。
- 三区:这个区域最为典型的代表是传统互联网企业。它们大多诞生在云平台大面积使用之前,主要基础设施仍是租用数据中心的物理机(或者虚拟化环境)。由于互联网行业的快速发展和激烈竞争,这些企业都在实战中打造出了比较强的应用交付体系和能力,能够支持应用频繁并高质量上线。但是这类企业同样面临着资源获取困难的问题,企业内部经常会出现IT资源管理者和IT资源使用方的割裂,并未形成完整的自助式IT文化。
- 四区:这个区域就是典型的DevOps企业,其中很多都是新型创新性企业。它们一方面遵循持续交付的理念打造整个软件交付平台,另外一方面积极采纳包括公有云在内的各种新型IT基础设施,帮助团队建立自服务IT门户,让每一位企业员工都可以自由获取IT资源,按照自己的要求快速交付需要的各种应用及服务。
参照如上DevOps能力坐标系,可以发现现实世界中很多一到三区的团队都在努力进化为DevOps团队,从而增加整个企业的IT服务能力和敏捷性。当然,不同类型团队在向DevOps团队演化的路径都各不相同。而且由于面临的行业和应用场景的不同,演化的节奏也有非常大的差异。但不论如何,作为希望构建DevOps团队的领导者,都建议去思考如下几个问题:
- 如果参照上面的DevOps能力坐标系,你的团队目前处在什么坐标?
- 如何定义团队的演化路径,且路径是否符合业务需求和团队实际情况?
- 在团队演化路径中,你需要什么样的资源或者工具支撑整个演化过程?
谈谈不可变基础设施(immutable infrastracture)
在讨论完如上的DevOps能力坐标系时,不得不提到最近两年非常火的一个概念,即“不可变基础设施(immutable infrastructure)”。作为这个术语的提出者,Chad Fowler(CTO at Wunderlist)是如下定义它:
servers (or whatever) are deployed once and not changed. If they are changed for some reason, they are marked for garbage collection. Software is never upgraded on an existing server. Instead, the server is replaced with a new functionally equivalent server.关于“不可变基础设施”的起源以及对此的各种讨论(尤其是它和配置管理关系的讨论),我这里就不展开详叙述,大家可以参考文章最后的参考链接。但是,如果把这个理念和上面的DevOps能力坐标结合起来看,就会是一个非常有意思的话题。如果说一个团队在DevOps能力坐标上处在非常优秀的位置(最右上角位置),则其可以快速获取基础设施资源并能够高效完成在资源上的部署与交付。那这个团队非常有可能选择“不可变基础设施”这种模式来交付自己的应用及服务(因为这会是最简单高效并可靠的方式)。当然,反之亦然。如果一个团队希望能够使用“不可变基础设施”方式交付应用,必然需要提升自身的IT自服务能力和持续交付能力,从而提升了整个团队的DevOps能力。从某种程度上说,“不可变基础设施”交付模式是DevOps能力发展的一个最好灯塔,尽管并不是每个团队或者应用都会采用这种交付模式。
最后,作为领先的混合云管理及DevOps协作平台,FIT2CLOUD在产品设计层就紧紧围绕帮助团队落地DevOps实践,提升DevOps能力这个宗旨。一方面,整个产品对接了国内主流公有云平台以及企业内部私有云与虚拟化环境,希望寄于此让尽可能多的用户通过云平台提升团队自服务IT上的能力。另一方面,FIT2CLOUD平台着力帮助用户打通从代码到服务的通道,提升用户的持续交付能力。而且整个产品对DevOps坐标系中两个纬度的能力做了合适的对接和整合,让两者能够协调起来,发挥出最大的生产力。如果您对于FIT2CLOUD感兴趣,欢迎随时试用我们的产品或者联系我们(support@fit2cloud.com)。