
MinerU是一款开源的高质量数据提取工具,能够将PDF文档转换为Markdown和JSON格式。2025年6月13日,MinerU发布了v2.0版本,相较于v1.0版本实现了架构和功能的全面重构与升级。在优化代码结构和交互方式的同时,v2.0版本还集成了小参数量、高性能多模态文档解析模型,能够实现端到端的高速、高精度文档理解。实际测试表明,新版本对复杂图表的解析效果较上一版本有明显提升,目前已经能够满足90%以上的复杂文档解析需求。
值得一提的是,MinerU出色的PDF文档解析能力特别适合与MaxKB开源项目配合使用。通过"MinerU+MaxKB"的组合方案,用户不仅能够获得高质量的文档解析效果,还能显著提升知识库问答系统的性能。为方便用户集成,MinerU项目现已提供API对接服务(https://mineru.net/apiManage)。接下来,本文将详细介绍如何通过MinerU在线API实现与MaxKB的对接。
一、实现方法
当用户提供文件地址后,系统会将该地址赋值给file_url变量,并作为参数传递给MinerU文件解析服务。MinerU在完成文件解析后,会返回一个任务ID(task_id)。系统会将其传入MinerU的查询接口,当检测到任务处理完成时,自动获取结果文件的下载链接(full_url)。随后,系统执行文件下载操作,将结果文件保存到MaxKB容器的/opt/maxkb/download目录下。最后,系统会自动完成文件上传和智能分段处理,将内容存储到知识库中。
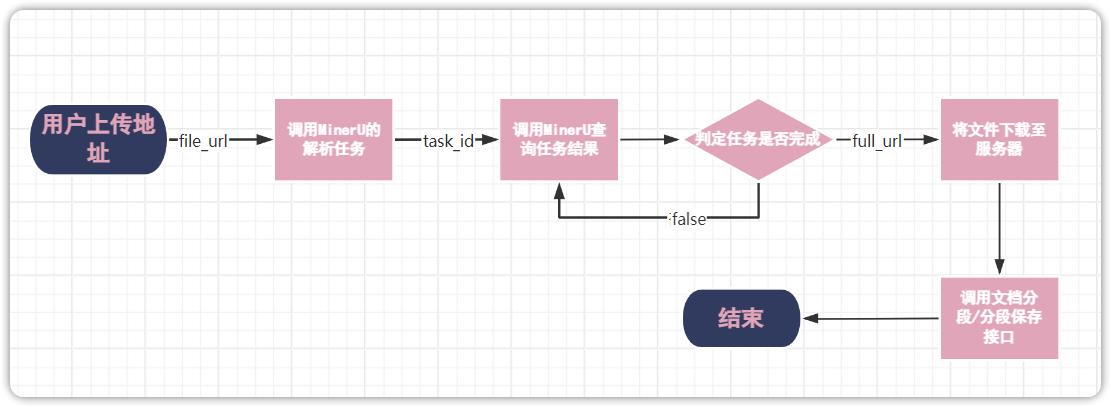
二、MaxKB函数创建
我们需要在MaxKB的函数库中创建四个核心功能函数,其用途分别为:
1. 调用MinerU单个文件解析;
2. 从MinerU获取任务结果;
3. 通过URL链接下载文件至服务器;
4. 将解析后的ZIP文件上传至知识库。
相关的代码说明如下:
■ MinerU单个文件解析函数:负责调用MinerU的单文件解析服务,通过传入PDF文档的在线地址来创建解析任务,并返回对应的task_id;
import requests
def create_task(file_url):
url = 'https://mineru.net/api/v4/extract/task'
token = '自己申请的 Token'
header = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {token}'
}
data = {
'url': file_url,
'is_ocr': True, #是否启动 ocr 功能,默认 false
'enable_formula': True, #是否开启公式识别,默认 true
'enable_table': True, #是否开启表格识别,默认 true
'language': "ch", #指定文档语言,默认 ch,可以设置为auto
'model_version': "v2", #mineru模型版本,两个选项:v1、v2,默认v1。
}
res = requests.post(url,headers=header,json=data,timeout=5)
res_data = res.json()
task_id_data = res_data["data"]["task_id"]
return task_id_data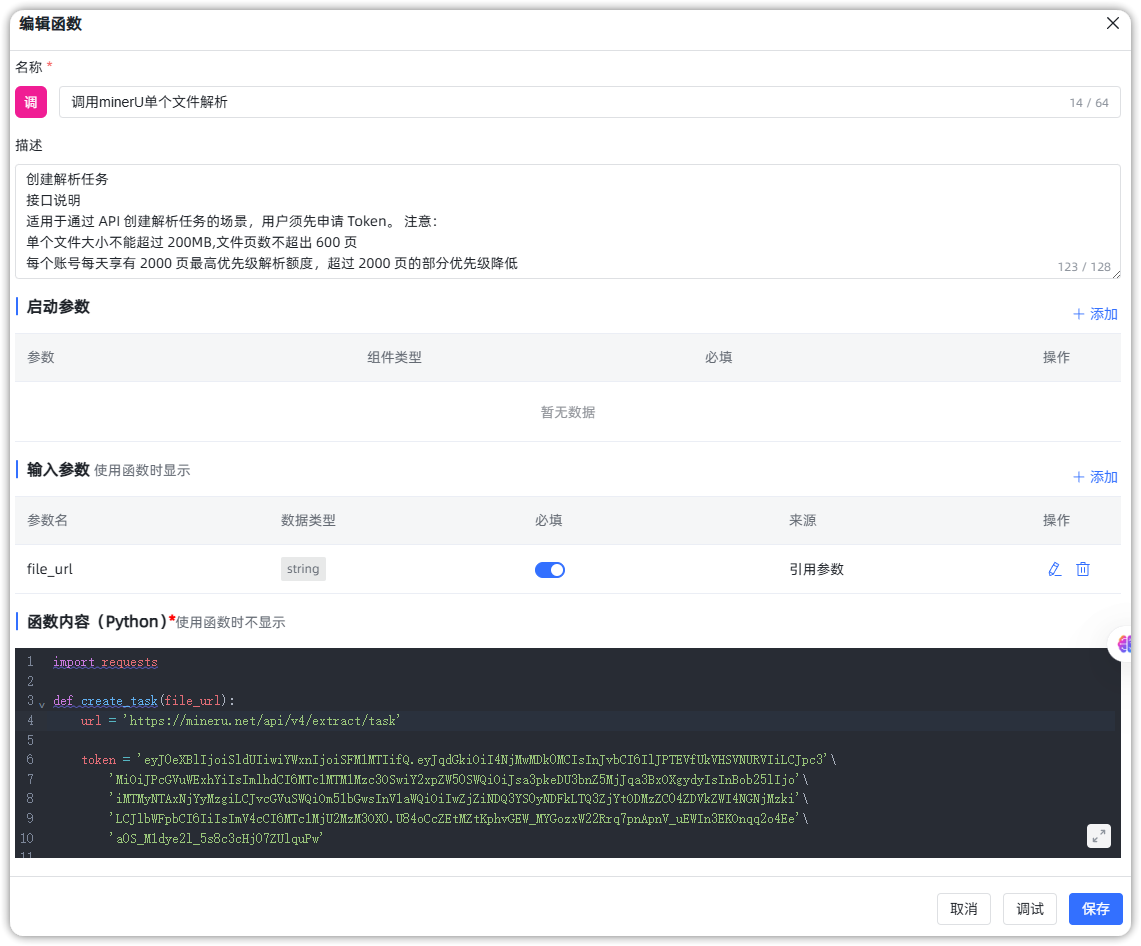
■ MinerU获取任务结果函数:用于查询任务状态,通过传入task_id获取解析结果,成功后将返回ZIP格式解析文件的下载地址;
import time
import requests
def querybyid(task_id,max_retries=100,retry_interval=5):
url = f'https://mineru.net/api/v4/extract/task/{task_id}'
token = '申请的Token'
header = {
'Content-Type': 'application/json',
'Authorization': f'Bearer {token}'
}
retries = 0
while retries < max_retries:
try:
res = requests.get(url, headers=header, timeout=5)
res.raise_for_status() # 检查请求是否成功
data = res.json()
if "data" in data and "full_zip_url" in data["data"] and data["data"]["full_zip_url"]:
return data["data"]["full_zip_url"]
else:
print(f"full_zip_url 为空,正在等待任务完成。已重试 {retries + 1} 次,共 {max_retries} 次。")
time.sleep(retry_interval)
retries += 1
except requests.exceptions.RequestException as e:
print(f"请求失败,错误信息:{e}。正在重试...")
time.sleep(retry_interval)
retries += 1
raise Exception(f"在 {max_retries} 次重试后,仍未获取到有效的 full_zip_url。")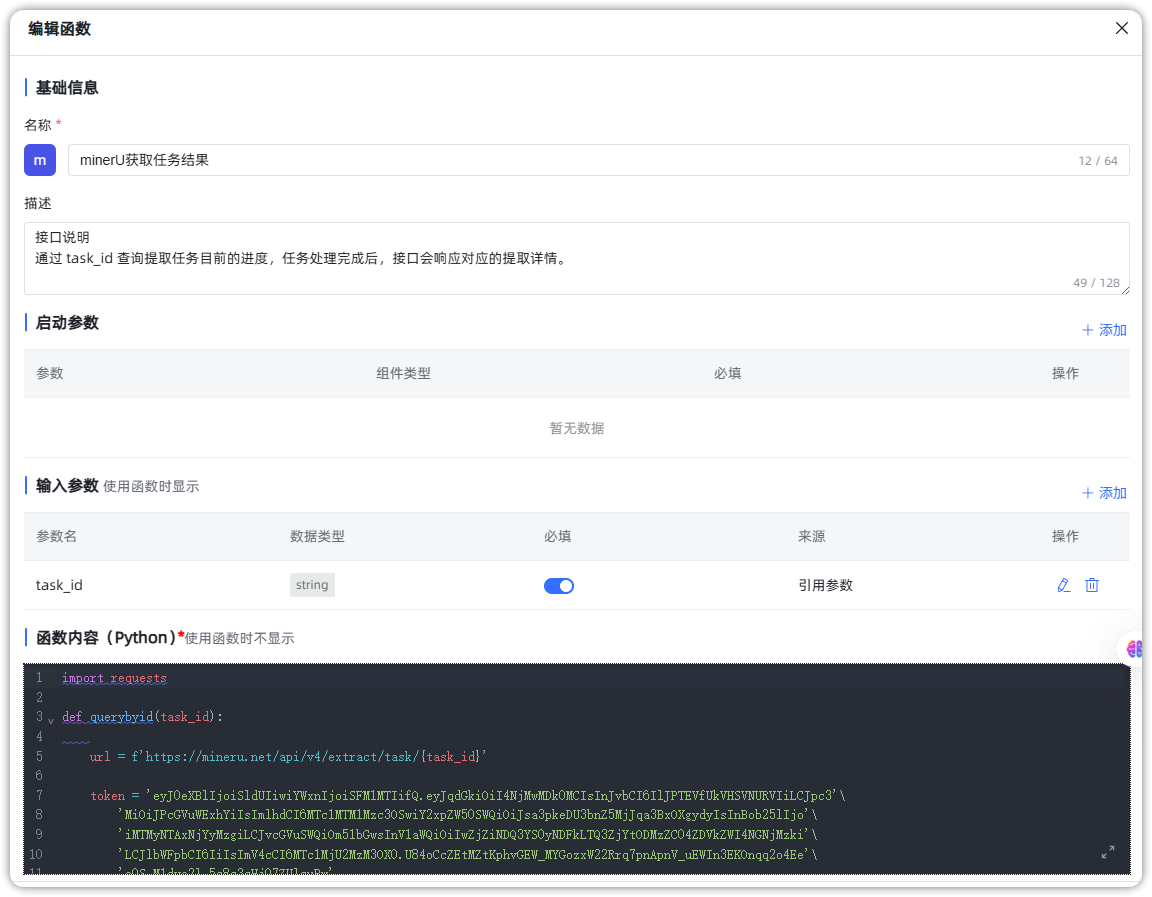
■ 文件下载函数:根据提供的ZIP文件下载链接,将文件保存至容器内的/opt/maxkb/download目录。需要注意的是,MaxKB默认使用sandbox用户运行,需确保该用户对/opt/maxkb/download目录有读写权限;
import os
import requests
from urllib.parse import urlparse
def download_file(download_url, save_dir='/opt/maxkb/download'):
os.makedirs(save_dir, exist_ok=True)
# 获取文件名
parsed_url = urlparse(download_url)
filename = os.path.basename(parsed_url.path)
save_path = os.path.join(save_dir, filename) # 文件下载后保存的目录,需要默认用户对此目录有读写权限
# 下载文件
try:
response = requests.get(download_url, stream=True)
response.raise_for_status() # 检查请求是否成功
total_size = int(response.headers.get('content-length', 0))
block_size = 1024 # 1KB
progress = 0
print(f"开始下载 {filename} 到 {save_dir}")
with open(save_path, 'wb') as f:
for data in response.iter_content(block_size):
f.write(data)
progress += len(data)
# 打印下载进度
print(f"下载进度: {progress / total_size * 100:.2f}%", end='\r')
print(f"\n下载完成: {save_path}")
return save_path
except requests.exceptions.RequestException as e:
print(f"下载失败: {e}")
return None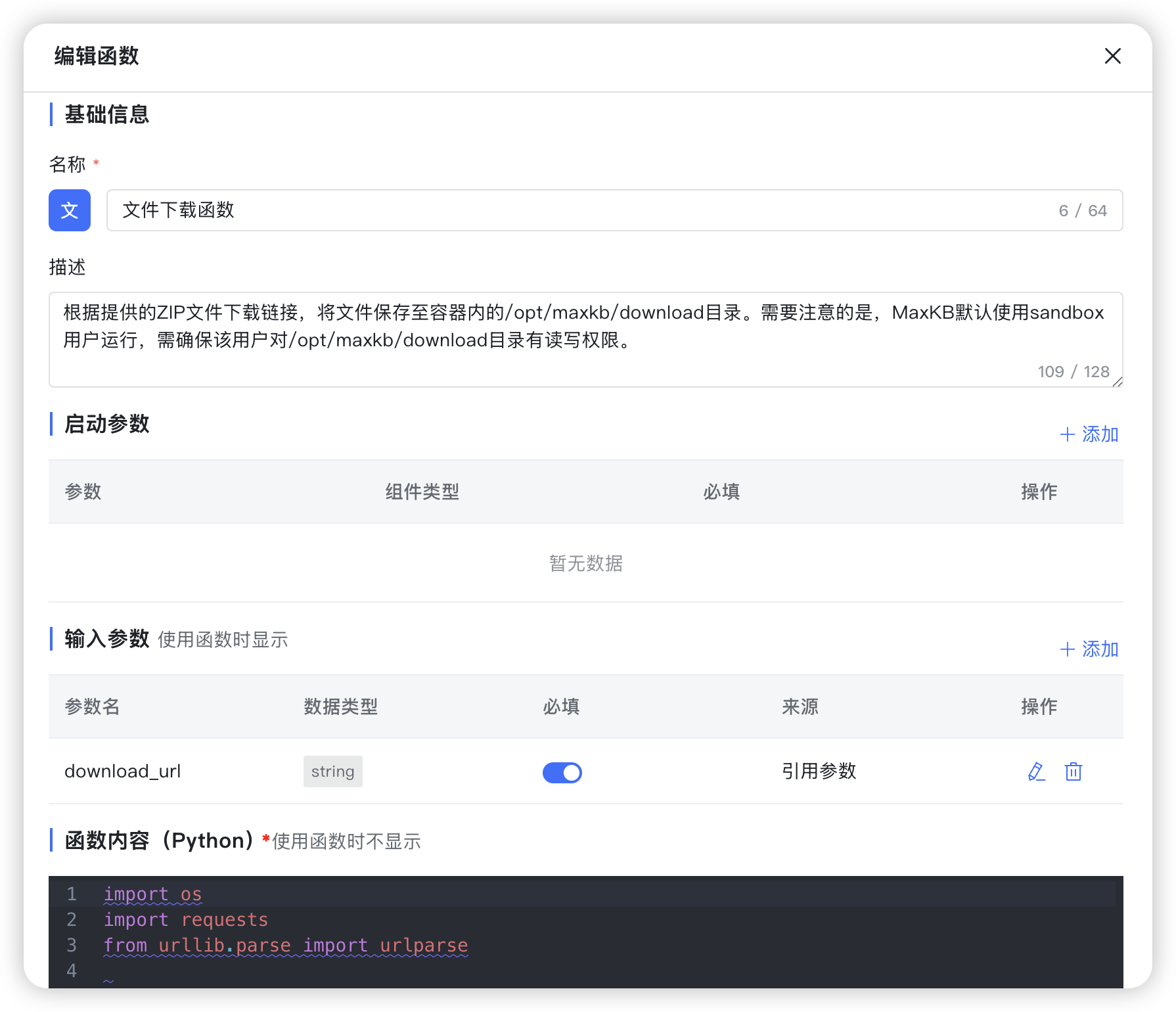
■ ZIP文件上传至知识库:通过MaxKB API将服务器上的ZIP解析文件上传至知识库存储。
import json
import logging
import requests
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
def initialize(file_path):
config = {
# MaxKB API密钥
'authorization_apikey': 'user-ac86ec515de17969f2f8a9c8ab21e52f',
# 文件分段处理的API地址
'split_url': 'http://10.1.11.58:8080/api/dataset/document/split',
# 目标知识库的API地址
'upload_url': 'http://10.1.11.58:8080/api/dataset/3d1d5d4e-5576-11f0-bc5c-0242ac120003/document/_bach',
'file_path': rf'{file_path}',
'file_name': '函数库上传文档分段'
}
return config
def upload_file(config):
headers = {
'accept': 'application/json',
'AUTHORIZATION': f'{config["authorization_apikey"]}'
}
try:
files = {'file': open(config["file_path"], 'rb')}
response = requests.post(config["split_url"], headers=headers, files=files)
response.raise_for_status()
response_data = response.json()
map_content = {}
for item in response_data.get("data", []):
for content_item in item.get("content", []):
map_content[content_item.get("title", "")] = content_item.get("content", "")
return map_content
except requests.exceptions.RequestException as e:
logging.error(f"文件分段上传失败: {e}")
return {}
except Exception as e:
logging.error(f"处理文件内容时出错: {e}")
return {}
def send_post_request(config, map_content):
headers = {
"Content-Type": "application/json",
"Authorization": f'{config["authorization_apikey"]}'
}
paragraphs = [{"title": key, "content": value} for key, value in map_content.items()]
document_wrapper = {
"name": config["file_name"],
"paragraphs": paragraphs
}
json_body = json.dumps([document_wrapper])
try:
response = requests.post(config["upload_url"], headers=headers, data=json_body)
response.raise_for_status()
logging.info(f"上传文件响应: {response.text}")
return True
except requests.exceptions.RequestException as e:
logging.error(f"上传文件失败: {e}")
return False
def main(file_path):
config = initialize(file_path)
map_content = upload_file(config)
if not map_content:
logging.error("文件分段上传失败或内容为空,程序终止")
return False
if not send_post_request(config, map_content):
logging.error("文件上传失败,程序终止")
return False
return "文件已上传成功,并保持在知识库中"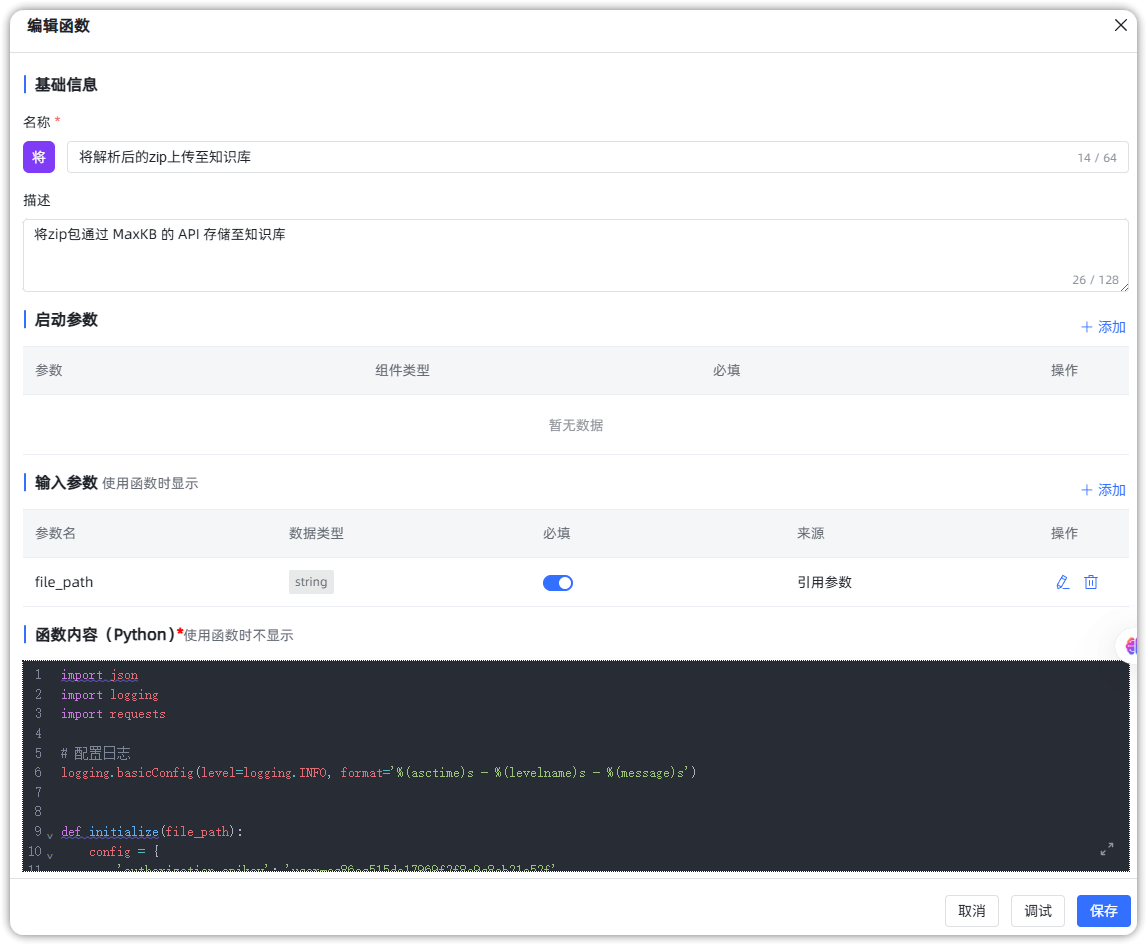
三、在MaxKB中创建应用
在上述四个函数创建完成后,我们可以在MaxKB中尝试创建高级应用。输入或提取上传文件的链接后,按照前文顺序依次添加MinerU单个文件解析函数节点→从MinerU获取任务结果函数节点→下载文件函数节点→文件上传函数节点。
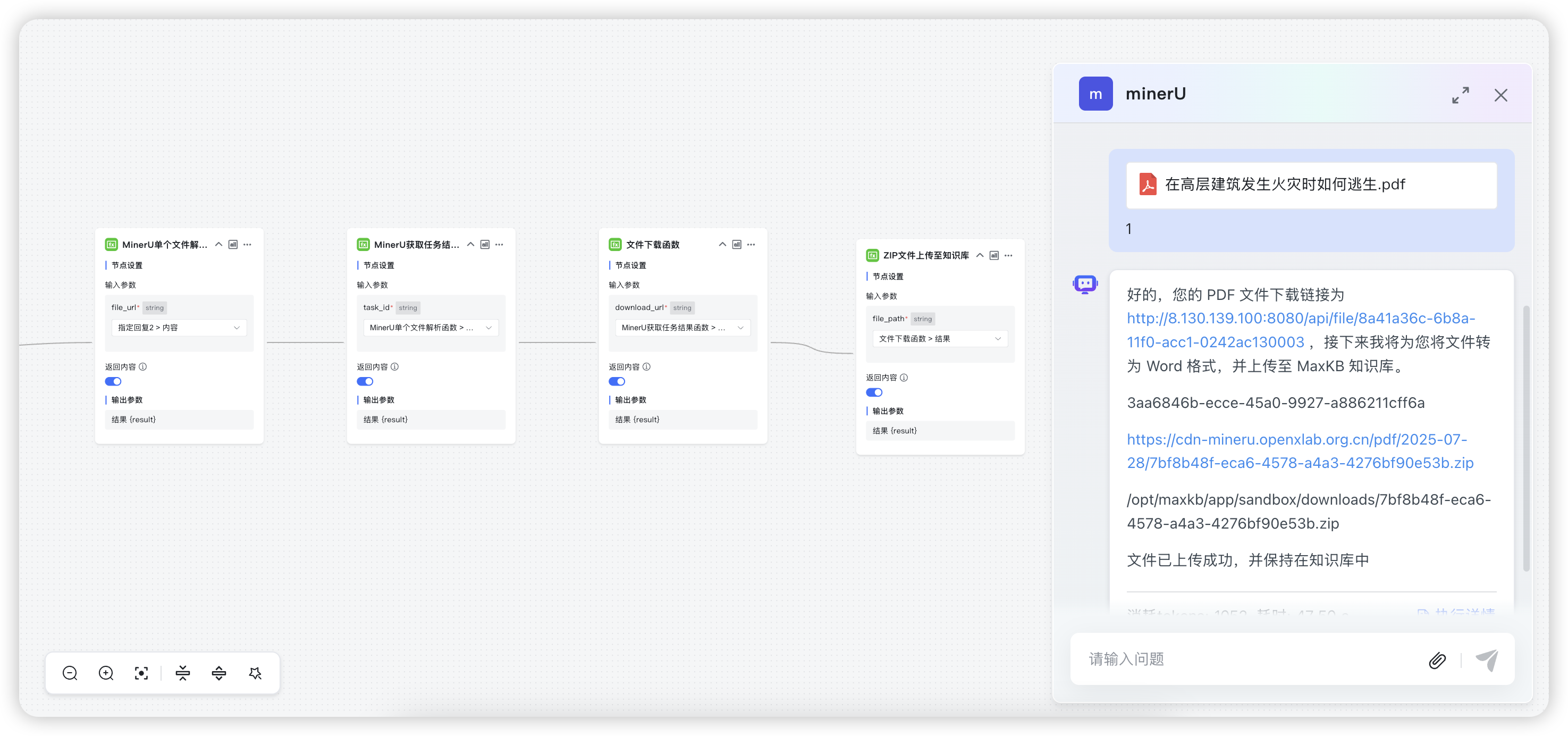
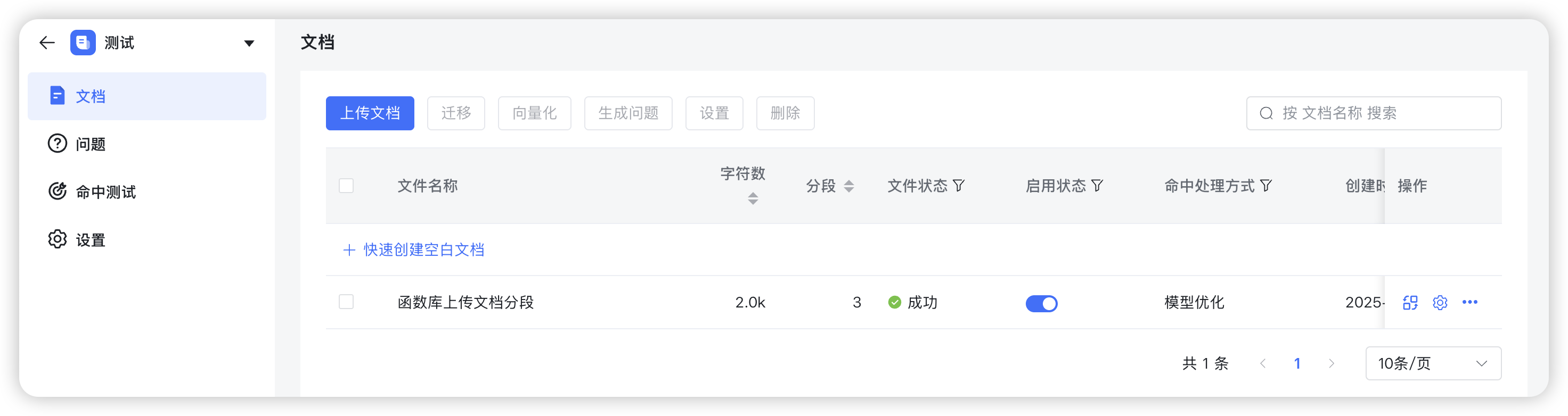
小助手提示“文件上传成功”,即可回到知识库页面,在目标知识库中看到新上传的文档。
总结来说,MinerU v2.0是一款开源、高性能的PDF文档解析工具,具备强大的多模态处理能力。通过MaxKB与MinerU的深度联动,可以基于函数调用构建清晰高效的 “文件地址→解析→下载→上传” 自动化流程,无缝衔接原始文档与结构化知识库的构建。
“MinerU+MaxKB”的组合方案,不仅可以显著提升文档解析的精度与效率,更能大幅增强知识库问答系统的能力与效果。
如果您对我们的项目感兴趣,欢迎下载并体验MaxKB!