
编者注:本文为知乎博主飞飞飞起来的原创文章。
原文链接:
https://zhuanlan.zhihu.com/p/502299146
前两天观看了DataEase开源项目官方的DataEase开源数据可视化分析平台X-Pack功能详解直播,虽然是抱着了解X-Pack功能的目的去观看的,不过最后却被直播前半段演示环节所吸引了。
我目前正在学习数据分析这块的内容,对Kaggle平台也比较熟悉。在Kaggle平台上,泰坦尼克号属于经典入门级分析的数据集。参与这个分析的人很多,经久不衰,参与分析的大多都是很专业的人员,使用Python进行数据处理和图表生成。
我现在还不具备这样的代码能力。之前也没深度地使用过DataEase,对它的了解不多。看到这次直播的演示,感觉自己终于可以尝试做泰坦尼克号的数据分析了。
数据获取
第一步,到Kaggle平台上搜索并获取泰坦尼克号的数据集。Kaggle平台上只要注册了账号并登录就可以直接下载数据文件,上面还有好多不同主题的数据集供用户使用。
DataEase平台搭建
第二步,搭建一个DataEase平台。具体的搭建步骤可以到官方提供的在线文档(https://dataease.io/docs/installation/online_installation/)上了解安装方式。还是挺简单的,使用一键安装命令的方式很快就部署完成。几分钟的时间就可以访问到刚部署好的DataEase,过程非常顺利。

数据准备
第三步,准备数据层面的内容。直播介绍的DataEase的使用流程是:数据源→数据集→仪表板。
因为刚刚从Kaggle获取到的数据文件是CSV格式的,但是DataEase目前对于数据的文件类型上只支持Excel格式。因此要么将CSV文件转成Excel文件上传,要么将CSV数据导入到数据库后再接入到DataEase上。考虑到后者可以锻炼自己的数据库能力,我就选择了第二种方法。
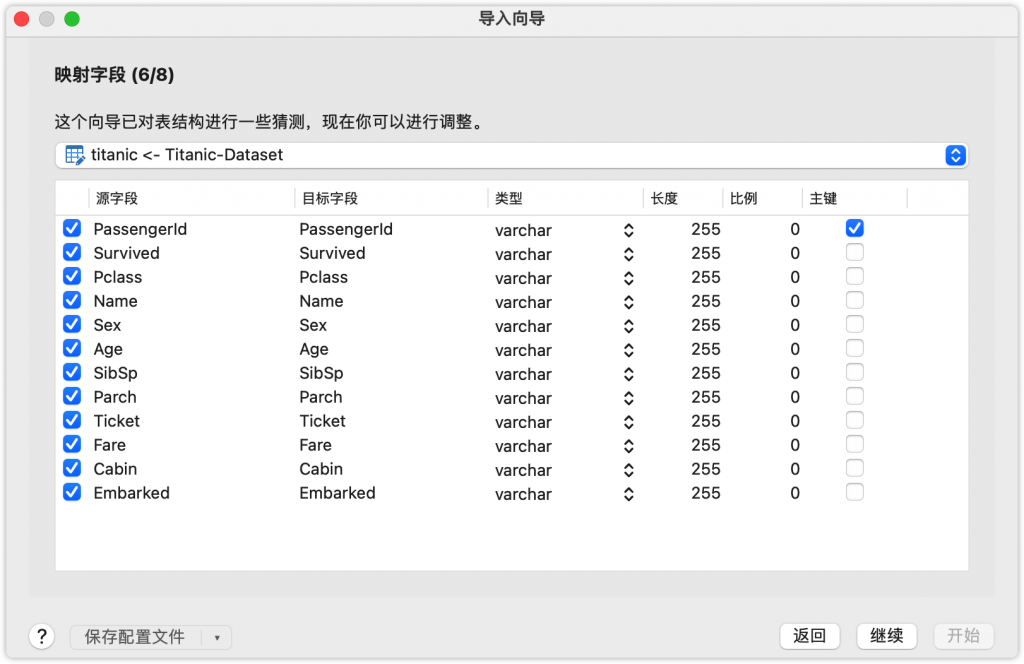
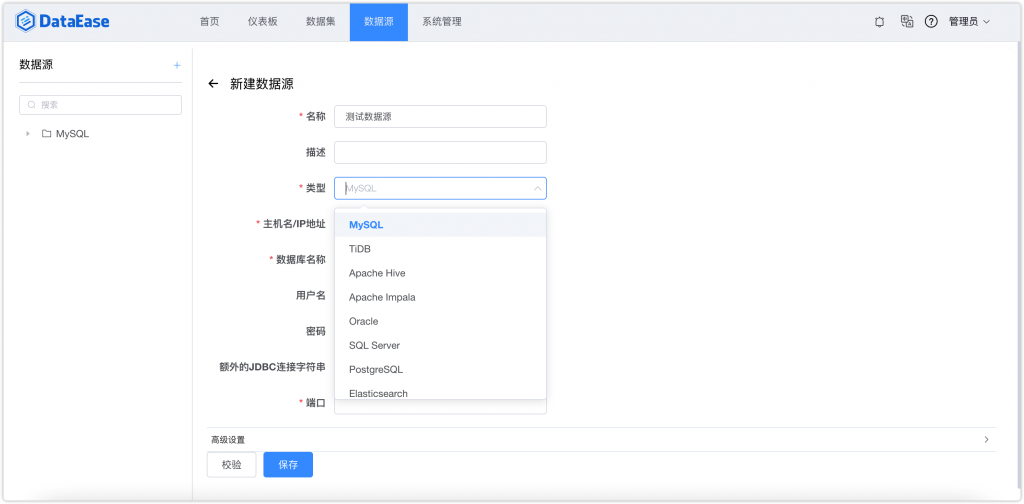
接下来我按照官方的在线文档配置数据源、数据集,一切都水到渠成。数据源这里我使用的是MySQL数据库。
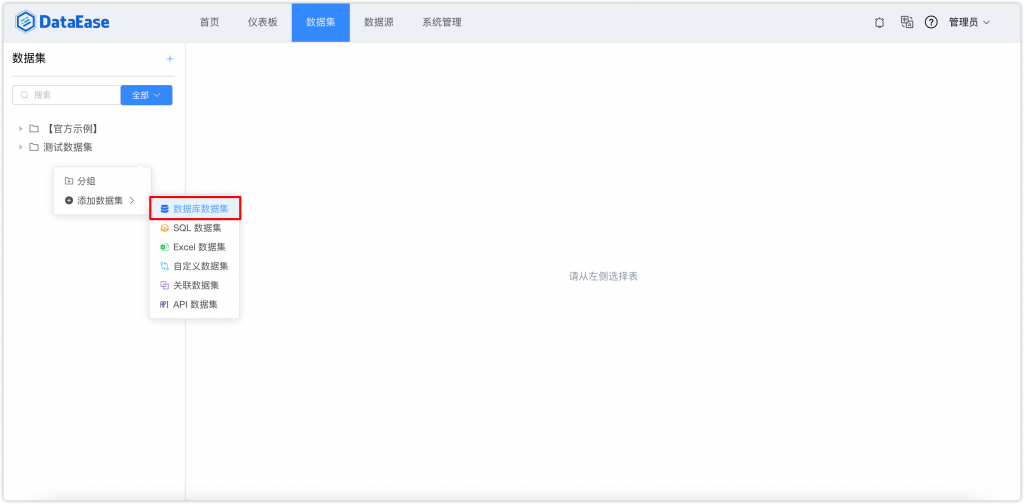
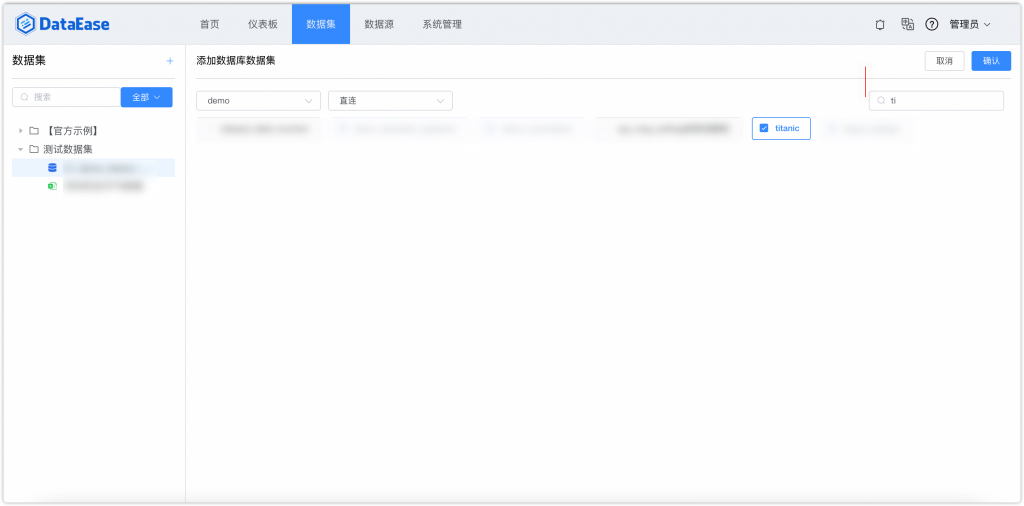
数据集我选择了数据库数据集,这样可以直接选择刚才导入的泰坦尼克号表。
按照直播里边所演示的,我这边也对原始的英文字段名在DataEase上做了重命名,以便于标识。
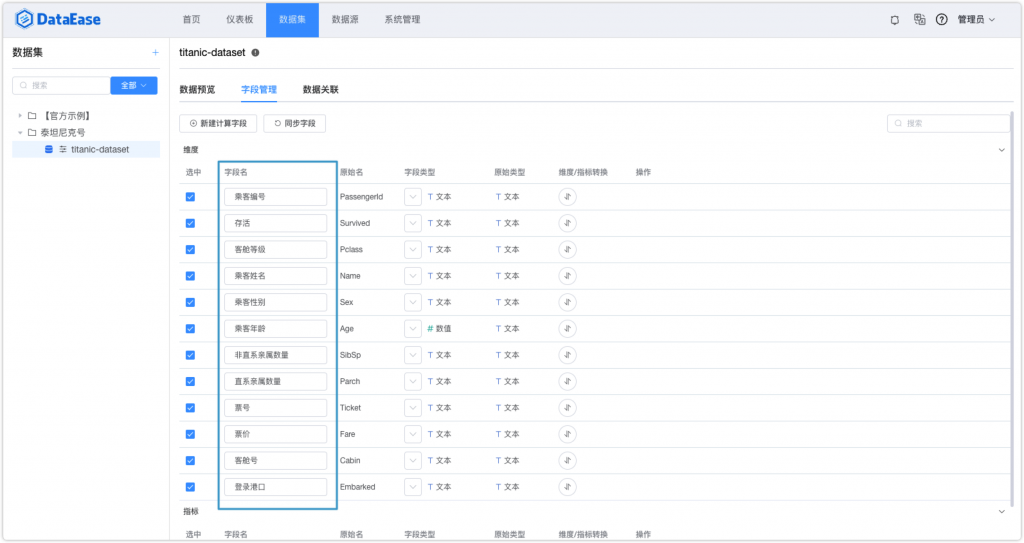
数据处理是数据分析过程中重要的一步。所以对于导入的数据集,我还需要通过DataEase的计算字段对部分数据内容进行进一步的处理:
■ 存活的替代值(0、1)转换为真实含义(未存活、存活);
■ 客舱等级(1、2、3)转换为更为准确的描述(一等舱、二等舱、三等舱);
■ 乘客性别(male、female)转换为中文的描述(男性、女性);
■ 乘客姓名里有一些关键词可以提取出来做对应关系,例如Mr→成年男士、Mrsr→已婚妇女、Officerr→政府人员、Royaltyr→王室成员、Masterr→技工、老师、Missr→未婚女子;
■ 亲属数量总数:非直系亲属数量+直系亲属数量。
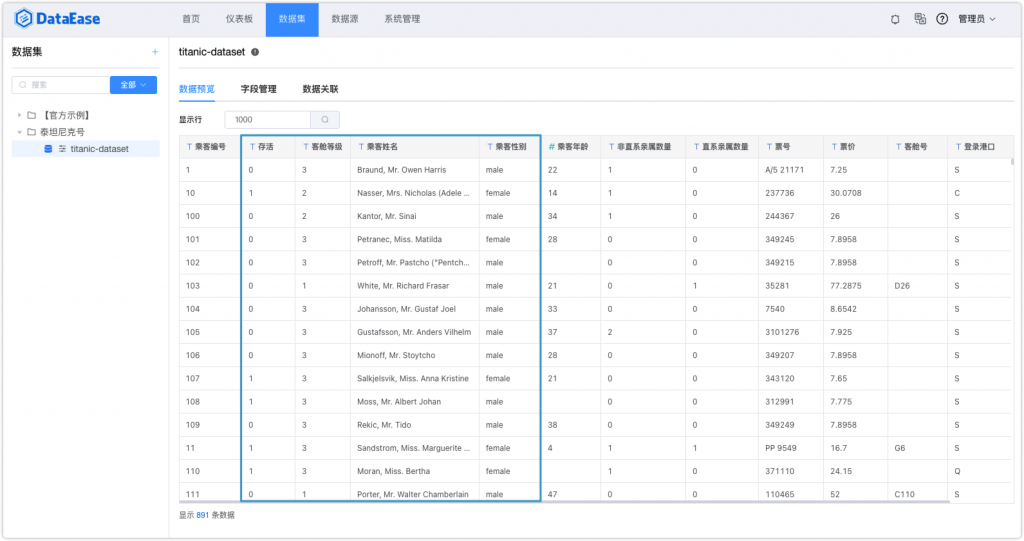
接下来我对上述需要梳理的内容一一进行处理,例如通过CASE函数做是否存活的数据字典映射。
DataEase的计算字段提供了搜索以及函数用法的解释,而且在FIT2CLOUD飞致云的知识库里也找到了一篇解释这个功能的相关说明(https://kb.fit2cloud.com/archives/47)。不得不说,这个知识库中可查阅的资源挺丰富的,能够解答很多使用过程中会遇到的问题。
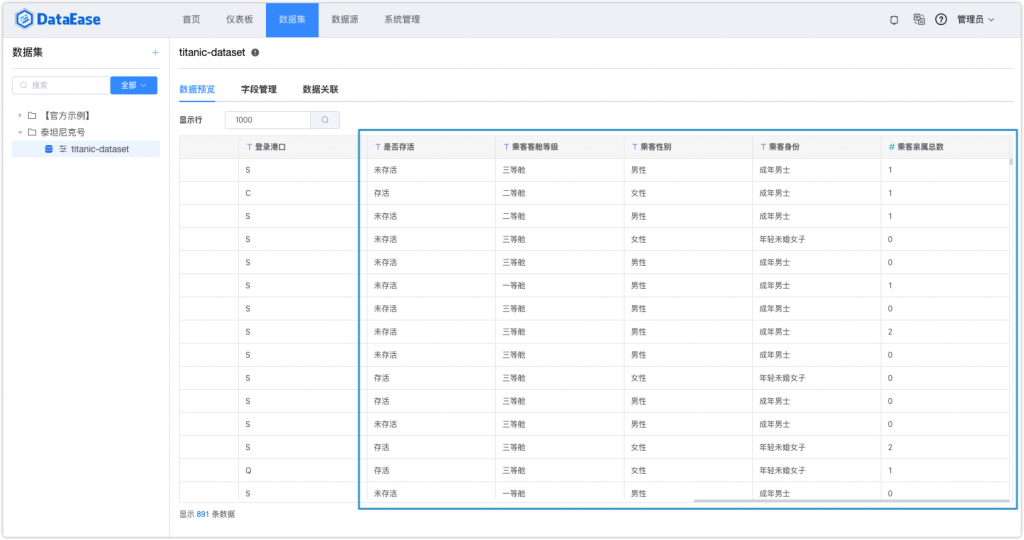
以上列出的全部字段处理完成的结果如下图所示。
数据分析
数据准备就绪后进入正题。通过数据分析,看看各类要素对这场事故的存活率产生了怎样的影响。在正式分析之前,我需要将几列数据排除出本次分析:
■ 乘客编号字段。该字段主要作为本次数据的唯一ID,没有太多实际含义;
■ 票号字段。没有太多相关性的属性,如果票号连接的话比较大可能是同一家人,本次暂时不考虑该变量的分析;
■ 票价字段。该字段基本与客舱等级呈现正相关的关系。不过也有少数票价为0的情况,可能会有一些其他的原因,本次暂时不放在对存活率的分析中;
■ 客舱号字段。该字段缺省值太多,只有少部分用户有该数据,所以该字段也不做分析。
对数据进行筛选之后,可以正式开始通过图表进行分析了。
首先在DataEase上创建一个仪表板,DataEase本身提供了一些模板供用户直接使用,不过我这边的场景更多的还是分析为主,好看的模板倒是不重要,就先没研究了。
之前我已经看过了DataEase项目的线上文档和B站的教学视频,所以对于仪表板里的各种功能有了基本的了解。
DataEase本身的设计构想也很简单,口号是”人人可用“,所以功能都很容易理解。做图表的界面如下图所示,各种元素的设置都可以在右侧功能栏中快速编辑,元素调整完图表就自动应用上了,元素也都是通过拖拽拉取的方式进行操作的,没有太大难度。
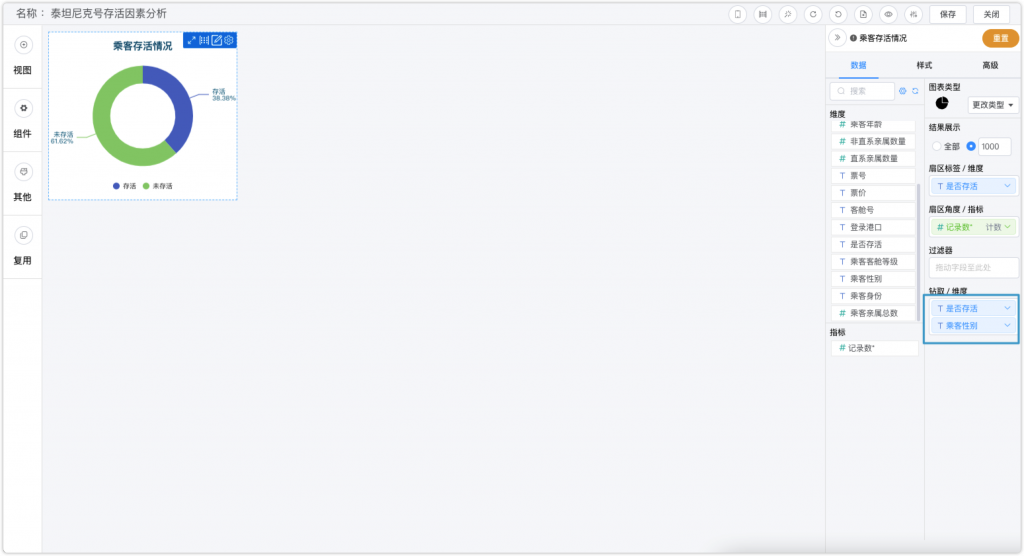
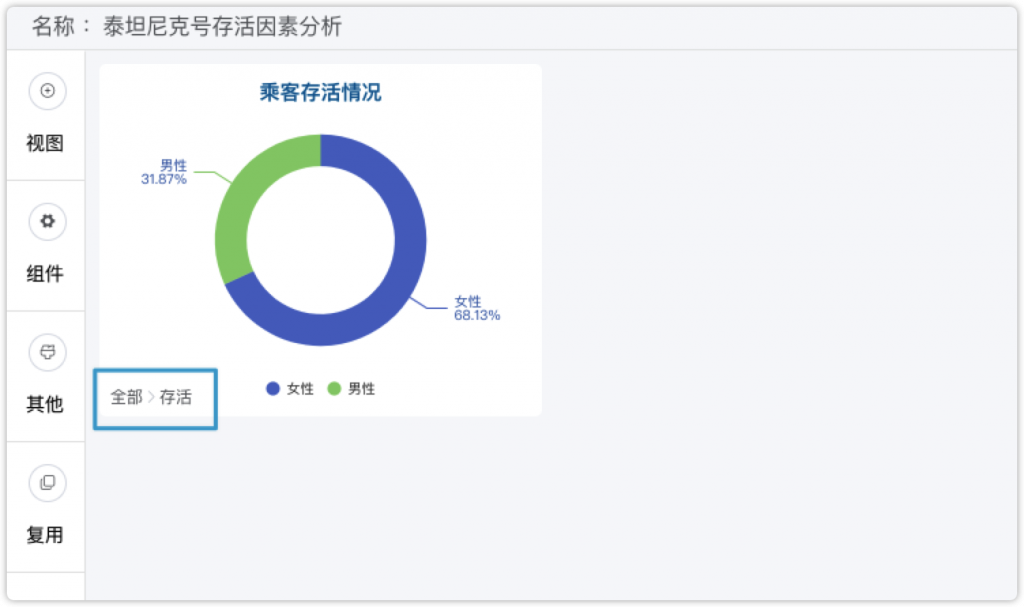
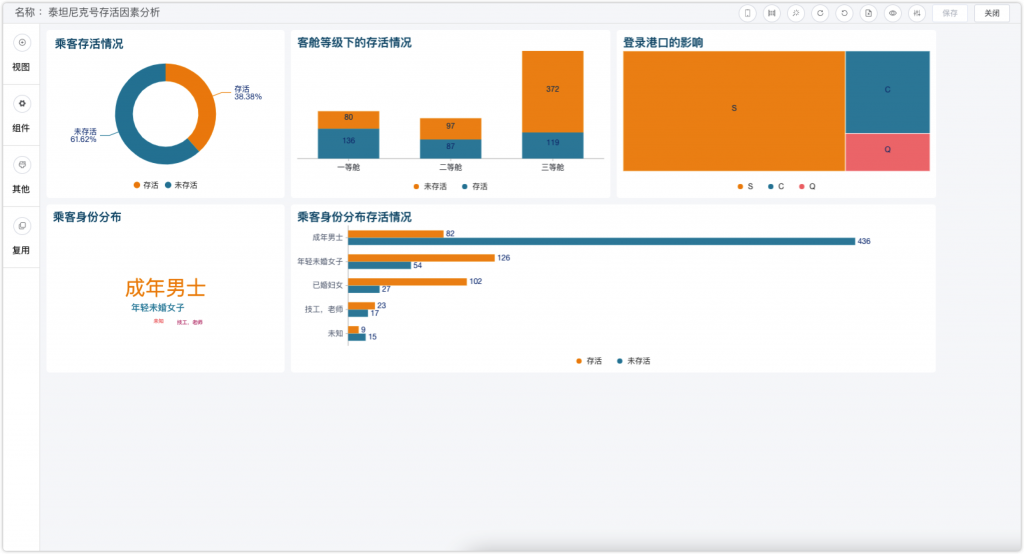
在需要分析的数据里,整体存活率的情况是需要优先关注的。在存活率的图表中,我还拖了两个字段到“下钻”那里,所以在环形图上点击一下,就可以看到二层乘客性别的情况。如下图所示,泰坦尼克号乘客的整体存活率为38.38%,而在存活的人中女性占比为68.13%。
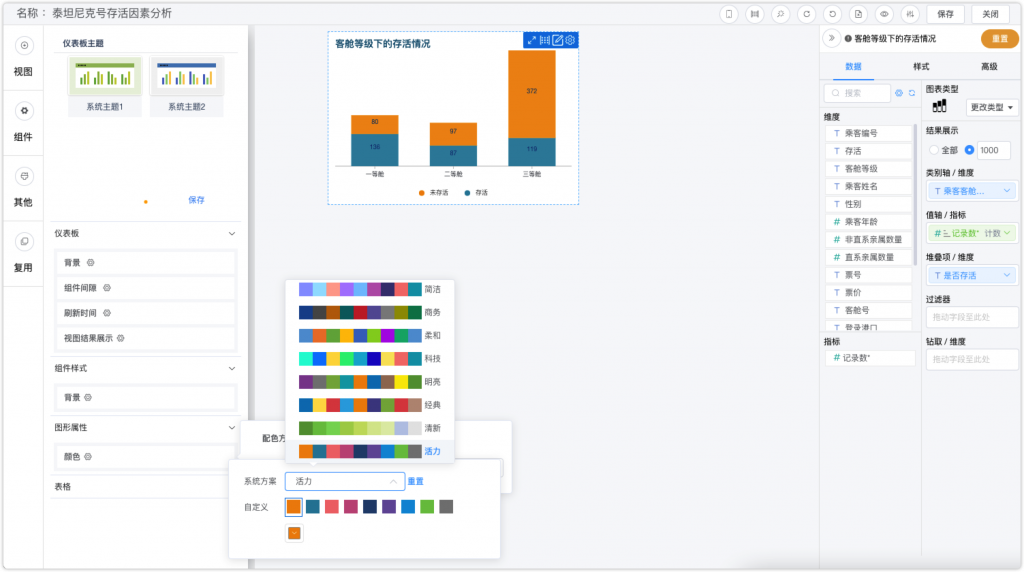
接下来我通过一个堆叠图对各个等级的客舱人员总数与存活数的分布情况进行分析。
堆叠图需要不同的颜色来提供差异,DataEase提供了一些可以直接拿来用的配色方案,也可以自己DIY,我最终选择了一个官方提供的配色方案。客舱等级的人数分布和影响因素的分析结果基本都在我的预想范围内,普通舱提供更多的座位,人数占比最大,一等舱的人员相对会分布更多贵族、有权势的人,所以一等舱的乘客有更高的存活率。
下一步对登陆港口的影响进行分析。
在这里我选择了矩形树图进行分析,并佐以钻取的操作。通过矩形树图的分布可以看到S港口的人员分布广泛,而通过下钻查看各个港口的生存情况,可以发现C港口存活率较高,人员最多的S港口存活率低下。
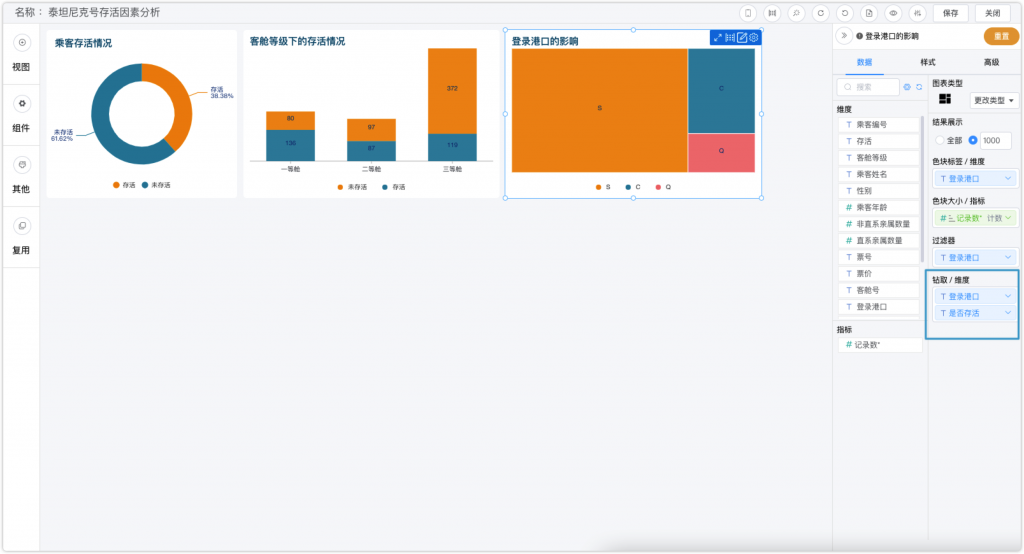
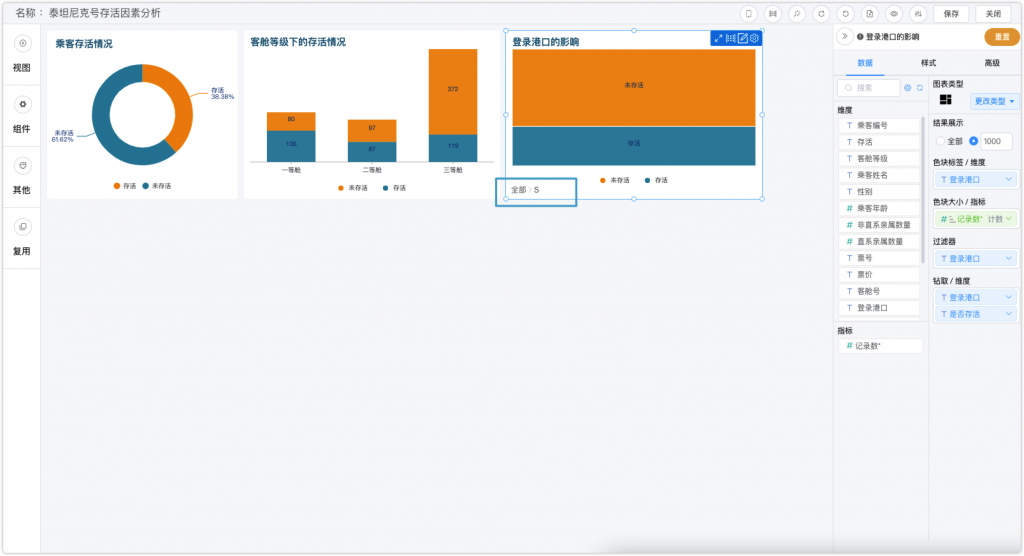
由于港口和存活率并没有直接的关系,所以我猜测可能与港口所集中的人员阶级有关,也就是说可能间接地与客舱等级有所关联。
为了验证这一猜想,我在图表上设置了数据联动,将客舱等级的图表中客舱等级字段与登陆港口图表的客舱等级做了关联,这样当我点击任一客舱等级,右侧登陆港口的人员分布随之联动,可以进一步对数据进行分析。
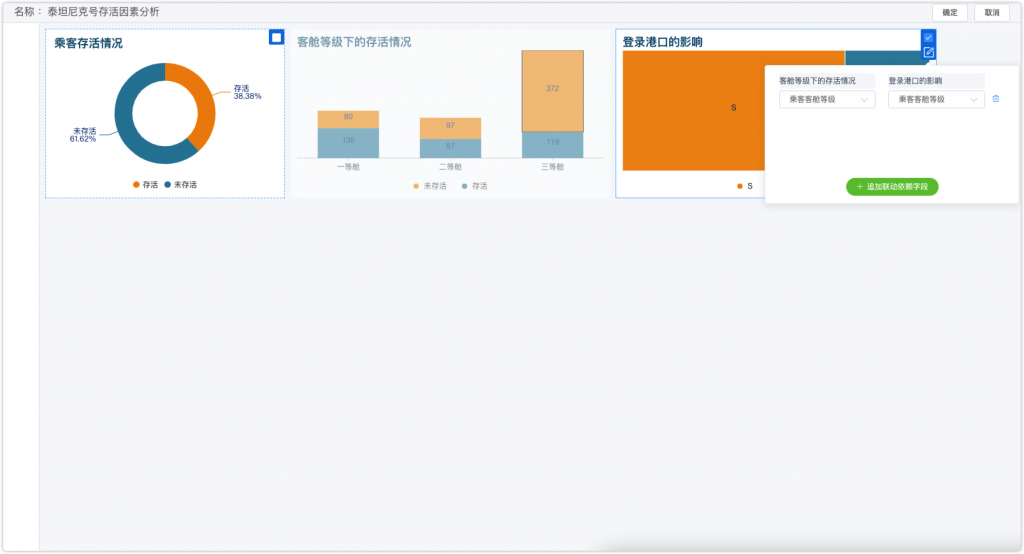
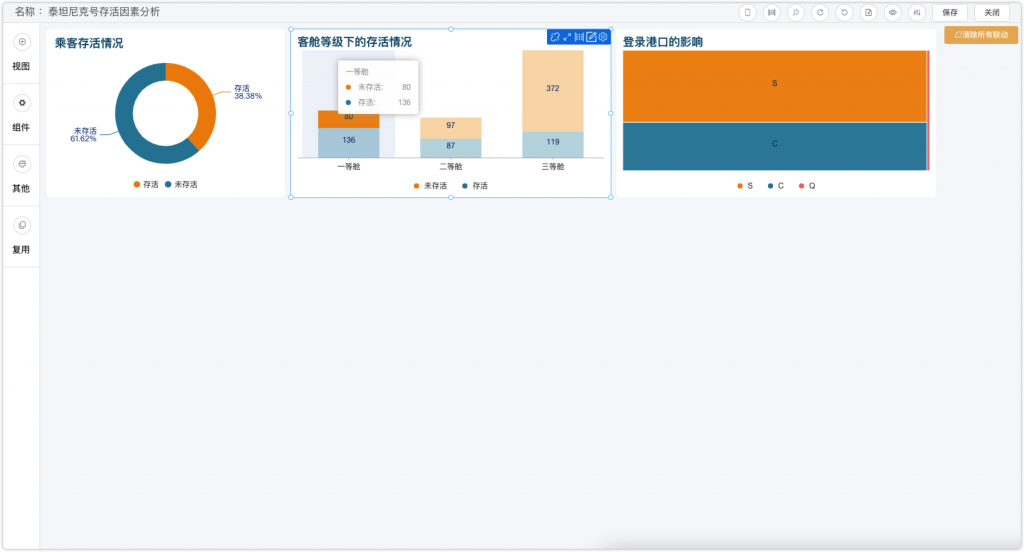
如图所示,当我点击客舱等级图表中的一等舱,右侧登陆港口图呈如下分布。可以看到,在存活率较高的C港口的人员分布中,一等舱人员的比例确实相对更高一些。分析完成后,可以点击右上角“清除所有联动”按钮,回到之前的界面。
下面我们对从乘客姓名中提取的身份信息进行进一步分析。如下图所示,我们可以看到成年男士的人数与生存情况。成年男性的存活率极低,猜测可能是因为有能力的成年男性承担了更多的责任,救助他人或者是让出了求生的机会,最终导致了这一结果。
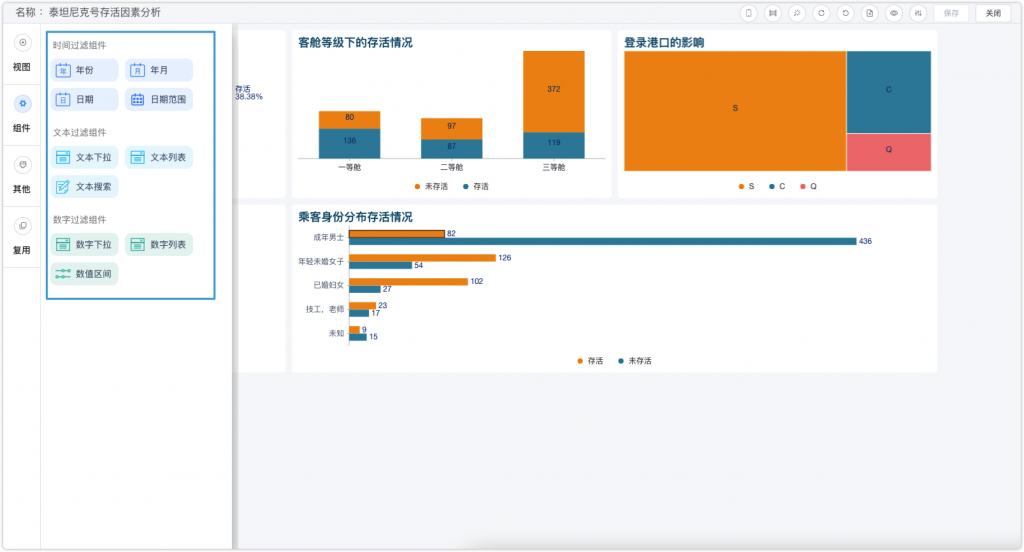
还有一些字段我打算采用筛选组件来分析,可以更灵活一些。通过分析年龄,我发现儿童的存活率还是比较高的,这应该是因为大家会优先保障孩童的安全。而对于直系亲属来说,有三个直系亲属(父母及小孩)的乘客获救的比例最大。
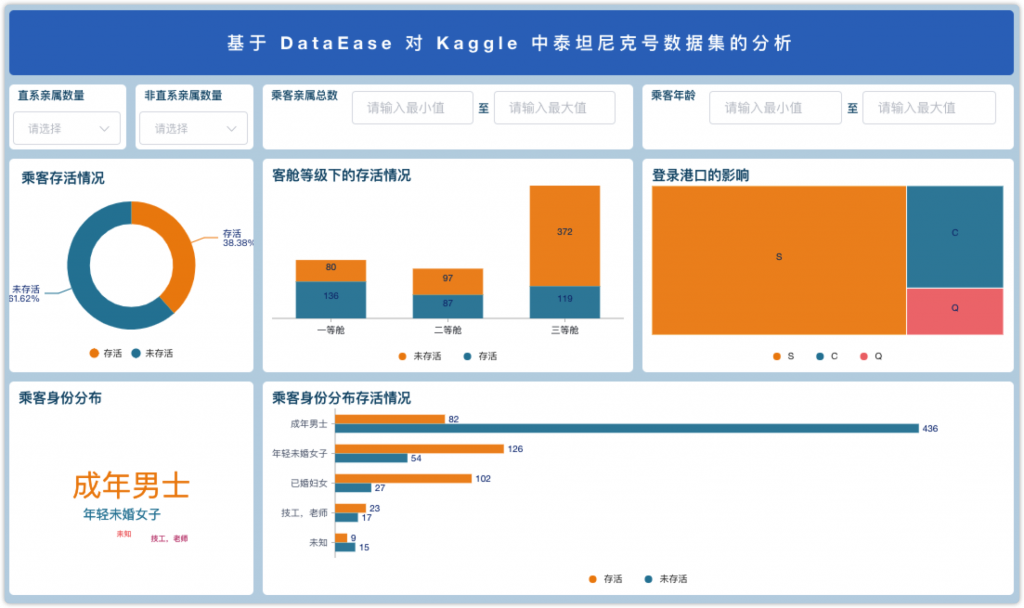
对已有的数据进行了图表分析之后,我再简单协调了一下仪表板的背景颜色和整体配色,并增加了一个文字组件作为标题,这样一个完整的仪表板就做好了。
至此,本次的DataEase开源数据可视化分析平台的试用就告一段落。由于一些分析是基于图表的下钻与联动,所以下图无法完全展现出上述所有的分析信息。每个分析情况在上述过程中都对应讲解过,这里就不再赘述了。
使用总结
DataEase开源数据可视化分析平台确实如其宣传语所说——“人人可用”。尤其是在仪表板的制作上,对于我目前想要的一些数据分析场景基本能够覆盖到,例如数据字段的简单处理、图表的下钻、联动等。成功帮助Python小白实现了网上大神做的一些分析效果。
此外,DataEase还有提供很多丰富的组件,像图片、视频、流媒体、网页等。不过我这次的场景里暂时用不上,下次可以再找几个好玩的数据集试试这些组件。
在实际使用的过程中,我也发现了DataEase开源项目一些可以提升的地方:
■ 建议增加CSV文件的支持;
■ 建议计算字段中显示真实的字段名。
总的来说,使用DataEase进行数据分析的过程还是很顺利的。希望这款开源工具能越来越好,迭代开发出更多好用强大的功能,我也会继续保持关注。