
作者:刘涛
2014 年底,AWS 在“re:invent”大会上发布了三个新的部署、管理服务 CodeDeploy ,CodeCommit 和 CodePipeline。此前 AWS 已经提供 Beanstalk,Opsworks,CloudFormation 等部署与管理服务,那为什么 AWS 仍然会继续在部署、管理服务上发力呢?用户有哪些问题还没有得到很好解决呢?本文将深度剖析这三个服务之一:CodeDedploy,剖析 CodeDeploy 解决的问题,以及阐述我们对其背后的原理和思想的理解。希望籍此能够吸收 Amazon 的经验并应用于改进和加速我们的开发交付过程。
1. CodeDeploy 是什么?
CodeDeploy 是 AWS 提供给其用户的自动化部署服务,能够让 AWS 用户方便快速地将应用自动部署到 EC2 实例上。通过部署流程的标准化和自动化,加快部署的速度,控制部署节奏,降低应用升级更新的复杂度,减少手工部署操作的错误和风险。最终使得用户能够在快速地发布新特性的同时保证部署的质量,避免部署过程中的服务中断。在支撑规模上,该服务能够处理成千上万节点规模的应用部署,能够满足绝大部分用户的部署规模要求。目前该服务仅在 AWS 美东 Virginia 和美西 Oregon 开放。
2. CodeDeploy 的来源
2014 年 11 月,Amazon CTO Werner Vogels 在其博客中透露了 CodeDeploy 的来源及其背后的故事(The Story of Apollo - Amazon’s Deployment Engine)。
多年前,Amazon 为了加快研发交付的速度,从公司层面对系统架构和开发组织结构进行了调整。整个系统架构转向 SOA,将大型系统都拆分成规模较小、独立运行的 SOA 服务。开发组织也调整为一个个小型自治团队,由每个团队全权负责管理其 SOA 服务的开发和运维,而不是将开发和运维分开由不同的团队负责。这个变化之后,他们很快发现部署过程又成为了新的瓶颈,于是很多团队通过将其部署过程自动化来解决这个瓶颈。最初在系统部署节点规模小和部署要求比较简单时都可以应付,但是随着系统部署节点规模的增大,跨数据中心部署以及对服务 SLA 更高的要求,部署问题及解决变得复杂起来。为了避免各个团队重复解决相同问题,Amazon 构建了一个内部部署系统 Apollo,让团队不再因为部署而降低发布新特性的速度。据悉,现在 Amazon 内部每天有数千工程师通过 Apollo 部署服务,2014 年部署次数超过 5000 万次。
与此同时,Amazon 外部的很多其客户也遇到同样的问题,他们希望 Amazon 能够分享相关实践经验。于是 Amazon 基于 Apollo 发布了其公开版本,即 CodeDeploy。
说到这里,我们不禁要问,Amazon 的 Apolllo 及其公开服务 CodeDeploy 究竟是怎么解决开发运维中的部署问题? AWS 自身也是天天需要部署。这么复杂的一个系统,有着严格的 SLA,都能做到无 downtime 升级,背后的原理是什么?是怎么设计的?下面我们先来看一下 CodeDeploy 解决的具体问题,然后再看 CodeDeploy 背后的设计和蕴含的思想。
3. CodeDeploy 解决的问题
CodeDeploy 解决的主要问题在于配合 Amazon 组织结构及系统架构设计调整,加速业务的交付,处理应用的部署交付,使该环节不再是影响交付速度的瓶颈。
对于部署,很多人觉的很简单,没有太大用处,不值得在上面花费时间。但是实际上,可以说部署过程对整个开发交付运维过程,交付速度质量影响是非常大的,特别是对于分布式系统,系统比较复杂,组件比较多,部署节点规模很大,对系统有 SLA 要求时,其需求场景内涵和外延是很广的,处理场景包括不同应用类型和架构,不同的应用组件代码打包方式,不同的目标部署环境,不同部署过程要求,等等。 下面举一些部署要处理的场景。
1) 应用类型和架构不同
- 规模不同(小型应用,大规模分布式应用等);
- 架构不同(简单的,复杂的,各个业务领域的,Web 应用,平台系统等)。
2) 应用组件代码打包不同
- 应用系统代码打包范围不同(如所有组件都打在一起或分开打包);
- 应用 Build 库不同(S3,Nexus,Git, SFTP 等);
- 应用代码结构不同 (Java,C++,Python,Ruby 等)。
3) 目标部署环境不同
- 部署的基础资源环境不同(AWS,Azure,物理机等);
- 用途类型不同(开发,测试,试运行,产品,演示);
- 节点规模不同(几个,几十,几百,几千);
- 地域范围不同(单一地区,跨地区,跨国);
- 操作系统及运行环境不同(Ubuntu,CentOS,库包等);
- 遗留系统兼容要求不同(可以导入主机,需要新创建)。
4) 部署过程要求不同
- 各组件部署的频率不同(不同组件同一个阶段中不同,一个组件不同阶段不同);
- 部署工作流节奏不同(不同类型组件同时部署,按顺序,一个组件分批部署);
- 服务允许中断时间 SLA 要求不同(可以中断几秒,几分钟,几小时,不能中断);
- 部署花费时间要求不同(几秒,几分钟,几小时);
- 能部署的人的范围不同(只有某些人有能力部署,所有人都能够部署);
- 部署的权限要求(只有某些人有权限,不做限制);
- 部署过程的可视化;
- 部署后的验证。
对于 CodeDeploy,除去其将环境绑定到 AWS 外,其设计思想还是很通用的,能够处理以上绝大多数的场景。那么为什么 CodeDeploy 能够解决这些问题,消除部署瓶颈,保持灵活通用? 我们来看看它的设计原理和思想。
4. CodeDeploy 的设计原理和思想
核心设计 1: 针对 SOA 设计,灵活通用,局部独立部署
传统方式采用的是整体部署的方式。在我们实际的开发和运维过程中,简单应用的组件通常比较少,部署场景也比较简单,适合整体部署。但是,对于组件比较多的大型应用,我们发现往往每次部署升级仅涉及其中几个组件,部署过程中往往最复杂的地方是各个组件之间的连接配置,升级顺序的控制和数据库表结构的升级。如果采用 SOA 的方式,把一个大型复杂的系统分解为一个个规模较小、独立自治的 SOA 服务,相当于简化问题。一方面分解出的每个系统复杂度会降低,另一方面组件之间的连接配置会大大简化,这样部署也就相应地简化,更易于处理和保证部署质量。
CodeDeploy 着眼的就是将大系统分解为多个 SOA 服务,通过部署分解后的 SOA 服务来处理整个系统的部署。相当于把整个系统部署分成多个局部部署,分而治之,这就是微服务、SOA 的理念在部署环节的体现。
核心设计 2:应用代码与部署脚本是一体的
传统应用代码和部署脚本是分离的,基于很多不同的部署工具开发,如 Chef,Puppet,Ansible,或者开发人员自己写的 Shell,Python 部署脚本。由于系统的开发和运维由一个自治团队全权负责,所以将代码与部署放在一起就非常自然。从这一点也可以看出 DevOps 的理念,即消除 Dev 和 Ops 之间的鸿沟,统一 Dev 和 Ops 的目标和部署。另外,将应用代码与部署脚本一体化,也简化了代码和部署脚本的管理,避免代码版本与部署脚本版本需要对应的问题。其实,这种设计也简化了用户的使用过程,不需要额外再做部署脚本版本的管理了。
核心设计 3: 基于事件的部署流程
CodeDeploy 定义了一个基于事件部署流程接口,在接口定义中,定义多个部署文件拷贝源目标部署映射 (files -> source-> destination),以及部署中各个步骤及步骤之间的执行顺序 (ApplicationStop -> BeforeInstall -> Install -> AfterInstall -> ApplicationStart -> ValidateService),各个步骤要执行的脚本,执行超时时间和执行用户。如下图 1 所示,右边部分就是一个部署接口定义,在这个定义中,开发人员定义了停止应用步骤使用代码根目录下 scripts 目录下的 stop_server.sh 脚本,在部署应用代码前,即 BeforeInstall 时,BeforeInstall 步骤执行 scripts 目录下的 install_dependencies.sh 脚本安装各种依赖,启动应用步骤使用 start_server.sh 脚本,最后验证部署时使用 validate_service.sh 脚本验证。
可以说,这个接口的设计非常灵活通用,适用于非常广泛的应用和部署场景,比如不管应用组件代码打包是在一起还是分开,不管应用架构是否是 SOA,把适配各种场景的实现留给应用的开发人员,由开发人员针对不同的场景按需实现。而 CodeDeploy 处理应用版本信息的管理,部署组管理,部署过程各个步骤自动化协调控制, 执行指定的各个步骤的脚本和部署过程的可视化。
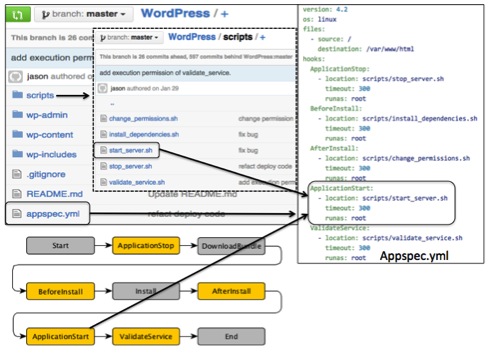
图 1: 基于事件的部署接口定义
核心设计 4: 对外开放 API
由于 CodeDeploy 只处理对基础环境 EC2 实例的部署,且只针对一个应用(组件),而实际过程中,一个系统包含了多个组件,那么整个系统的生命周期管理的整个过程需要自动化,所以 CodeDeploy 也开放了相应 API 接口以及 CLI,以便应用开发人员能够将 CodeDeploy 服务集成到自己的开发流程,实现持续交付。
5. CodeDeploy 的适用范围及局限性
应用生命周期管理包括配置管理,资源管理,环境管理,部署交付管理,自动化测试,监控告警,备份恢复及容量伸缩等各个环节,我们看到 CodeDeploy 仅处理代码部署问题,并不处理应用配置管理,资源管理,环境管理以及之后的监控和恢复,伸缩等环节。 其中:
- 配置管理中的代码版本管理在 AWS 服务中由 CodeCommit 或 Github 处理 ;
- 应用 Build 存储由 S3 处理 ;
- 环境管理,基础设施资源管理环节由 AWS EC2,Cloudformation 来处理。
所以,使用 CodeDeploy 完成应用的部署还需要集成使用 AWS 的 EC2,IAM,S3 等多种服务,才能完成静态代码到在线服务的整个流程。例如,使用 CodeDeploy 之前,需要先通过 AWS EC2 启动运行应用需要的实例,配置实例的部署组类型(例如,通过打 Tag),给实例配置访问 S3 的权限,并授权 CodeDeploy 操作实例权限等。由此可见:
- 用户要想实现系统的持续自动化部署,仍然需要自行集成开发, 比如需要自行实现应用新版本的打包和上传到 S3,之后调用 CodeDeploy Rest API 升级新版本;
- CodeDeploy 只能管理 AWS 上的应用,而无法用于管理跑在其他 IaaS 基础设施中的应用,不支持应用的跨云迁移和管理。
6. 总结
“You build it,you run it.” 是 Amazon CTO 信奉的理念,这个工具再次体现了这点。当然,它也体现了 DevOps 的思想,体现了 Amazon 的 SOA 架构。虽然 CodeDeploy 只能用于管理 AWS 上的应用的部署,不能用于管理我们国内云上的应用,但是我们还是能够从中借鉴很多理念和设计,调整我们的系统架构和组织架构,统一 Dev 和 Ops 的目标及工具,以加快我们的交付速度,提升运维的效率质量。
作者简介
刘涛是 AWS 认证解决方案架构师,FIT2CLOUD联合创始人。FIT2CLOUD 不仅提供一站式的应用交付及运维管理工具,同时还提供方法论来帮助企业打通从代码到服务的通道,实现云应用的持续交付和自动化运维。FIT2CLOUD 的代码部署功能和 AWS CodeDeploy 相似,兼容 AWS CodeDeploy 的 appspecs.yml 接口规范,同时,FIT2CLOUD 还支持用户导入外部主机进行统一的部署和管理。