
“智能问数”利用大语言模型(LLM)和自然语言转SQL(Text2SQL)技术,让非技术用户通过自然对话获取数据,从而大幅降低数据分析的门槛。然而在实际的应用中,由于大语言模型对特定业务和数据结构的理解存在局限性,大家在使用智能问数系统的过程中经常会遇到问数不准确、答非所问等情况。总结来说,用户在智能问数的过程中经常会遇到的挑战包括:
■ 答非所问:查询结果的统计范围或者筛选条件与用户意图不符,例如询问区域销量却返回了总量;
■ 结果不准:生成的SQL语句存在逻辑错误,例如生成SQL语句的时候表关联有误,导致查询结果不准确;
■ 无法生成:模型无法识别或者关联用户问题中涉及的数据表,导致SQL语句生成失败或者查询无法执行;
■ 术语混淆:模型不能理解特定的业务术语或简称(例如将JumpServer简称为JS),导致生成错误的SQL查询语句。
导致这些问题的根本原因在于,大语言模型虽然掌握了SQL语法,但是缺乏针对特定业务和数据库结构的业务上下文。为了解决这一问题,SQLBot开源智能问数系统(https://github.com/dataease/SQLBot)提供了完善的业务上下文配置机制,允许用户将业务逻辑和数据定义注入到让大语言模型能够理解的上下文中,从而生成更加符合用户意图的SQL语句。
本教程将为您介绍SQLBot业务上下文的具体配置方法,通过精准问数调优的四个步骤,您可以系统性地提升SQLBot在业务数据查询中的准确性。
一、SQLBot的业务上下文配置能力
SQLBot是一款基于大语言模型和RAG(Retrieval Augmented Generation,检索增强生成)的智能问数系统。它利用大语言模型的强大能力,将用户的自然语言问题实时转换为精确的SQL查询语句和可视化图表。其核心目标是让业务人员、运营人员乃至管理层都能在没有SQL基础的情况下,也能够轻松与数据库进行对话,即时获取数据分析的结果。
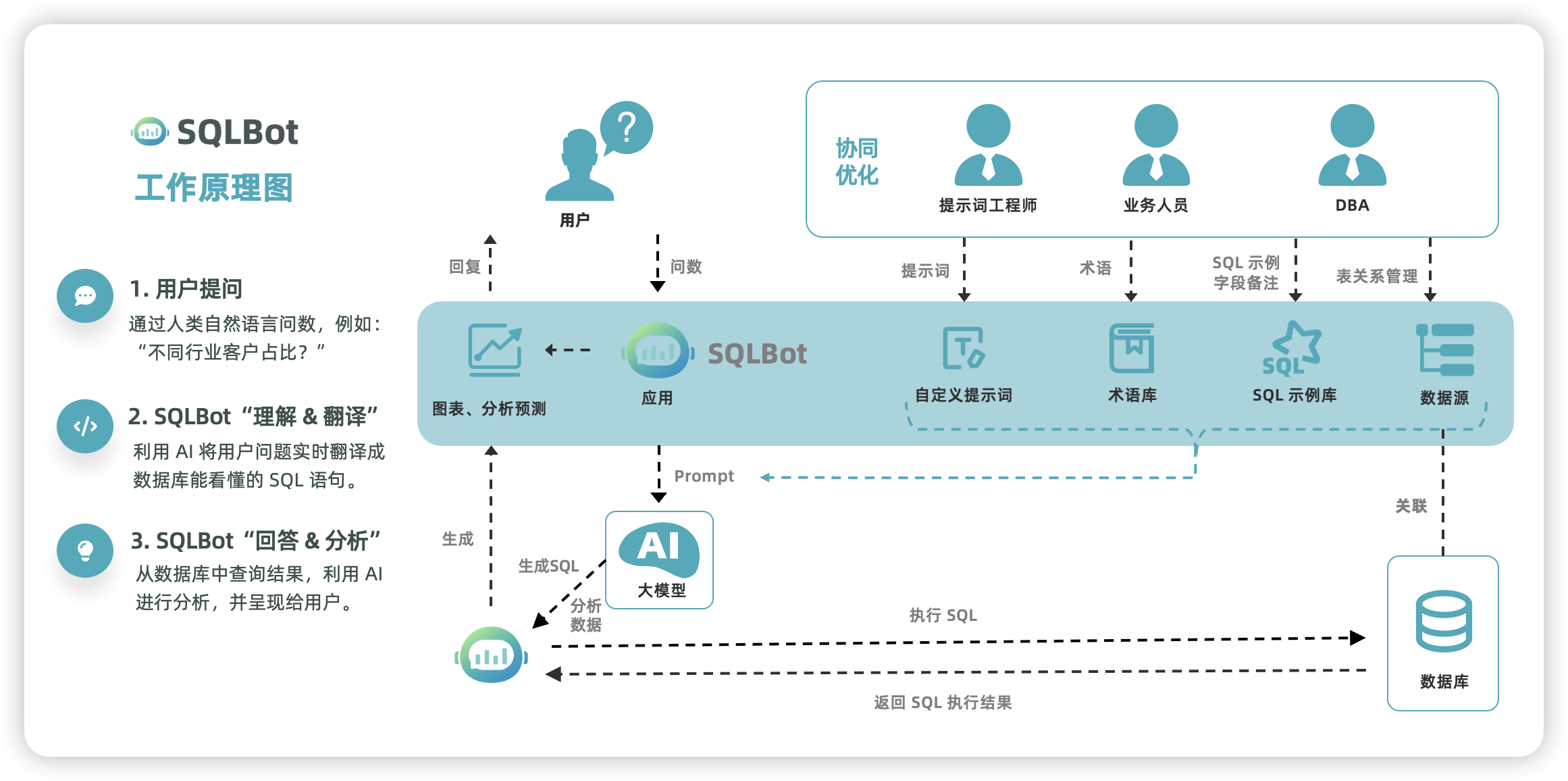 ▲图1 SQLBot的工作原理
▲图1 SQLBot的工作原理
为了解决大语言模型“缺乏业务理解能力”的问题,SQLBot提供了一套强大的业务上下文配置能力,主要包括四大核心功能:
■ 表管理:支持筛选、过滤、重命名数据库中的表和字段,并且支持添加业务相关描述,为大语言模型划定清晰的知识边界;
■ 表关联关系管理:通过可视化界面定义表与表之间的连接(JOIN)关系,确保大语言模型在处理跨表查询时遵循正确的逻辑,生成准确的SQL查询语句;
■ 示例SQL:针对业务中高频、复杂的查询,可以预先录入“标准问题”和“标准答案SQL”,供大语言模型来参考学习;
■ 自定义术语:建立业务术语、指标与数据库字段之间的翻译词典,消除大语言模型的歧义理解。
二、SQLBot四步调优:实现高效准确的NL-to-SQL
Cordys CRM(github.com/1Panel-dev/CordysCRM)是新一代的开源AI CRM系统。我们选择以Cordys CRM系统为问数对象,需要提前在SQLBot中接入Cordys CRM系统的数据库“cordys-crm”作为数据源,并将这个数据源命名为“CordysCRM”。
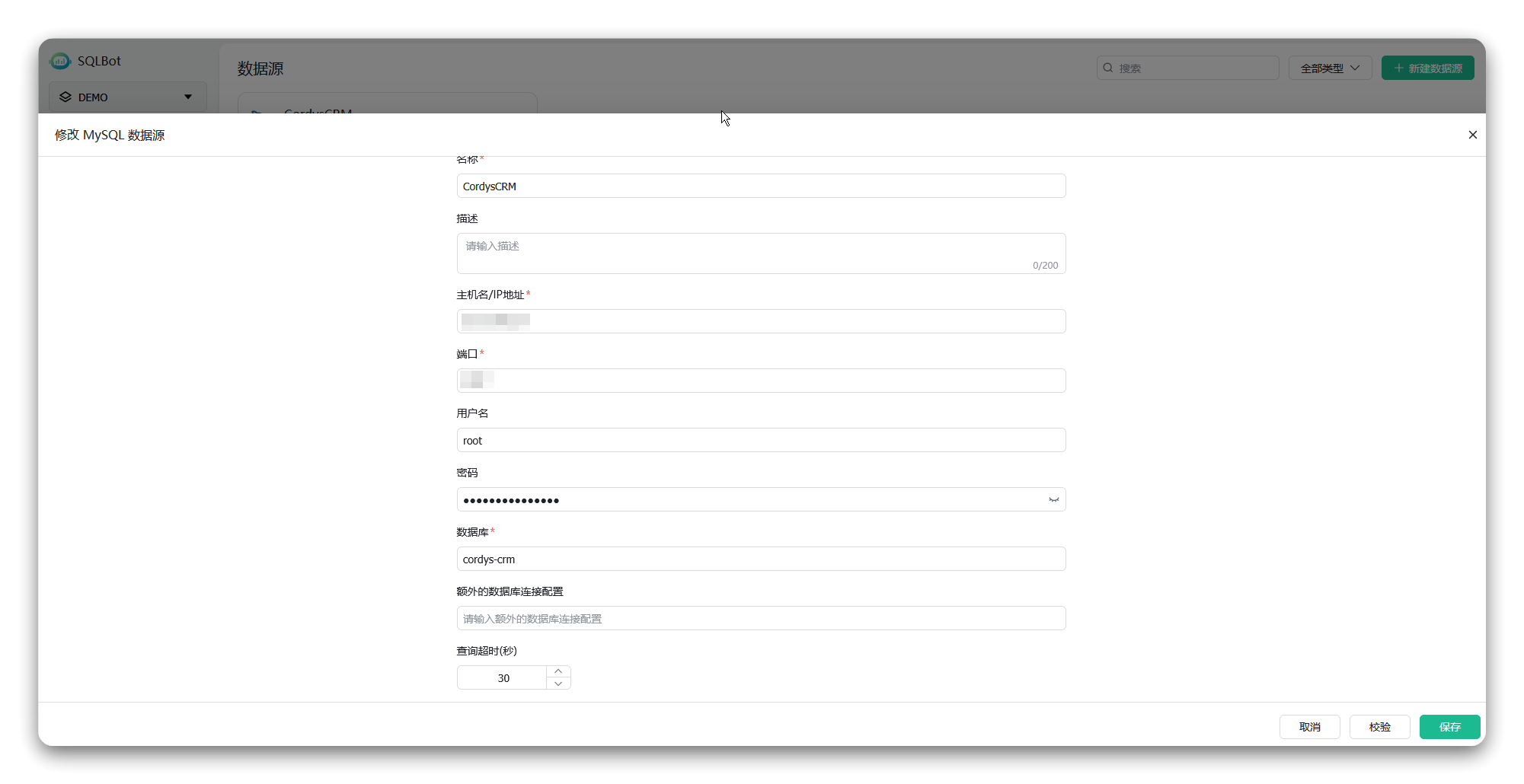 ▲图2 在SQLBot中添加名为“CordysCRM”的数据源
▲图2 在SQLBot中添加名为“CordysCRM”的数据源
第一步:精简数据源(表管理)
提高大语言模型生成SQL语句准确性的第一步,是划分其可用的数据表范围。例如,CordysCRM数据库中有93张表,其中一部分是系统日志表、配置表、任务表等与问数无关的表,如果将这些表也纳入“问数”的范围,不仅无用,还会干扰RAG通道中大语言模型生成SQL语句的准确率。
表管理功能用于划定大语言模型访问数据的清晰边界,避免模型被冗余信息干扰。表管理的操作方法如下:
1. 确定问数范围(隐藏无关表):
① 进入SQLBot中CordysCRM数据源的表管理界面,先加载所有数据库表;
② 剔除业务分析中不涉及的表,例如:“agent”表、“dashboard”表、“worker_node”表。
表管理的操作原则,仅保留业务分析所需的核心表(例如线索表、客户表、商机表、用户表等)。
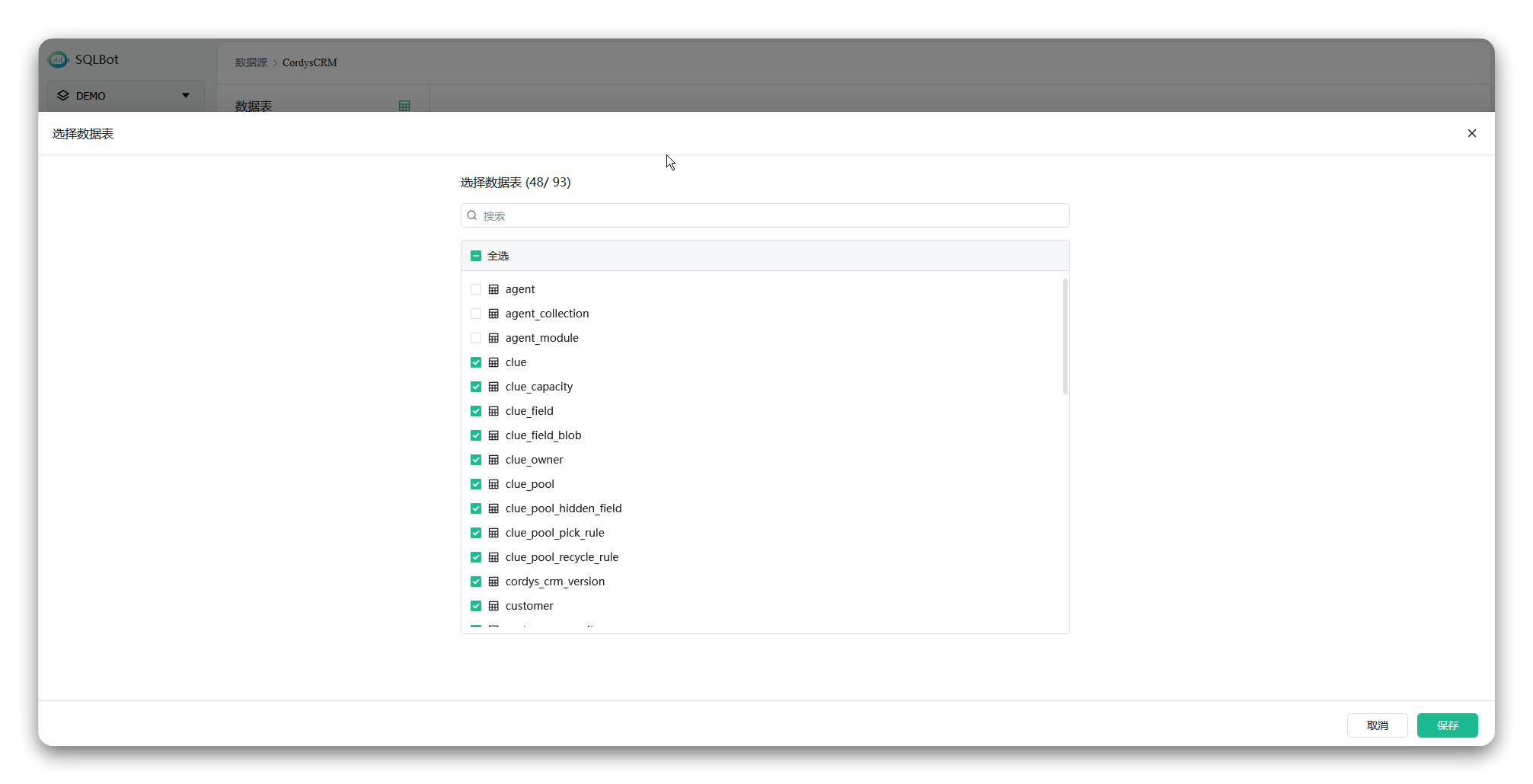 ▲图3 SQLBot数据源中的表管理操作界面
▲图3 SQLBot数据源中的表管理操作界面
2. 设置字段别名和描述:数据库中的表名和字段名通常过于技术化,无法适配自然语言的提问内容。这种情况下就需要设置字段别名和描述,让大语言模型可以更好地理解用户的自然语言提问。接下来将以CordysCRM数据源中的线索表“clue”为例进行说明;
① 设置字段别名:将“name”字段的原始备注改为“客户名称”,将“collection_time”字段的原始备注改为“领取时间”;
② 添加描述:这是提供业务逻辑的直接方式,也是提升SQLBot智能问数业务能力的最关键一步。
■ 为表添加描述
例如,为线索表“clue”添加描述:“线索表,包含所有已创建的线索信息,包括新建、跟进中、个人线索、部门线索等。”
■ 为字段添加描述
例如,为“线索状态”字段添加描述:“枚举值:FOLLOWING=跟进中,NEW=新建。”
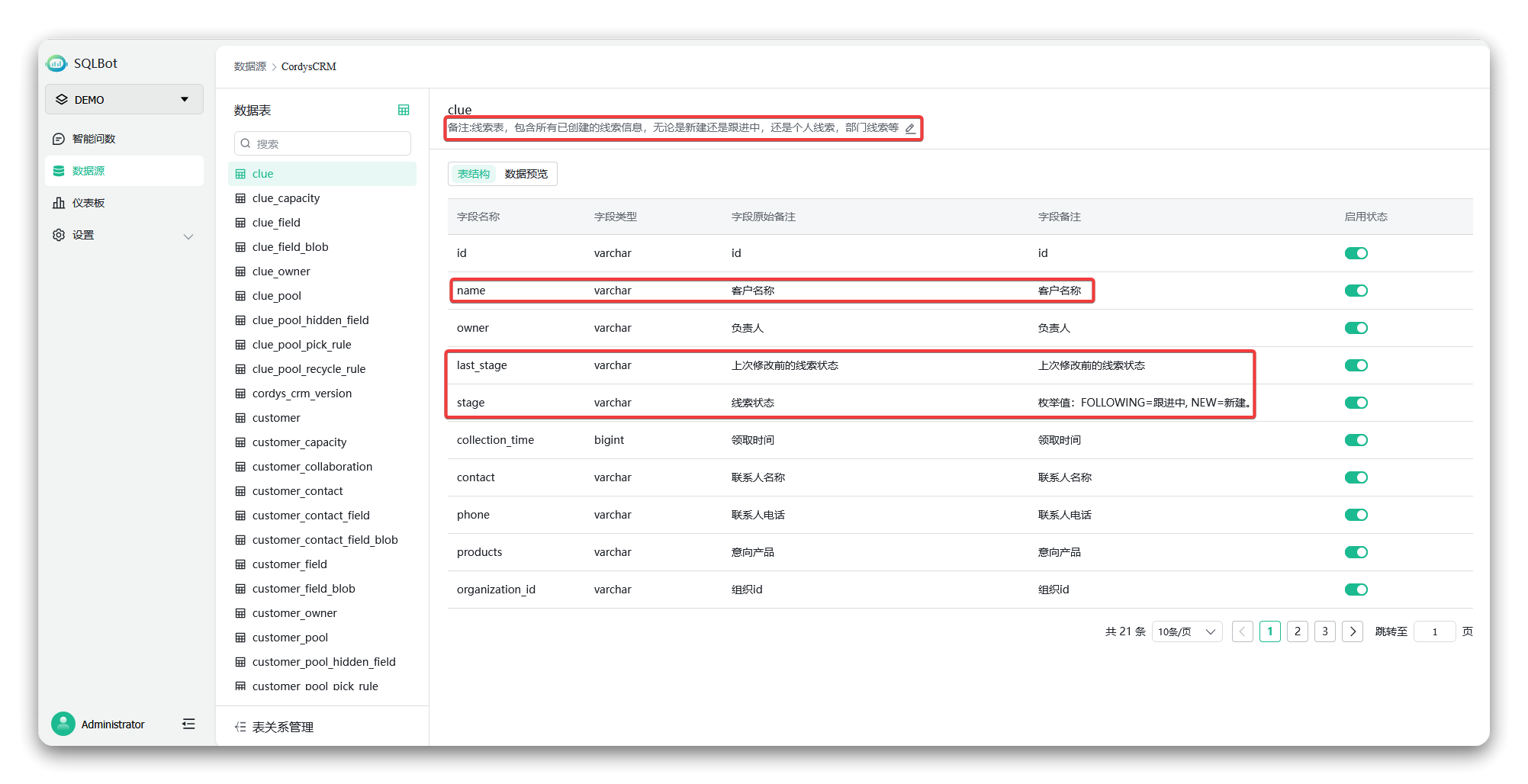 ▲图4 字段别名和描述设置
▲图4 字段别名和描述设置
第二步:明确表关联逻辑(表关联关系管理)
复杂的业务查询往往涉及多张表的联合查询(JOIN)。如果大语言模型不知道正确的表关联关系,就会导致生成的SQL语句关联错误和不准确。SQLBot的表关联关系管理功能可以用于为大语言模型提供跨表查询的明确关联关系。
表关联关系管理的操作方法如下:
1. 进入CordysCRM数据源的“表关系管理”界面;
2. 定义连接:通过外键连接的方式,手动定义表与表之间的关联关系。例如,定义一条连接规则,让线索表“clue”的organization_id字段关联组织表“sys_organization”的ID字段;
3. 覆盖所有核心业务关系:确保业务分析可能涉及的所有表都建立了正确的关联关系。
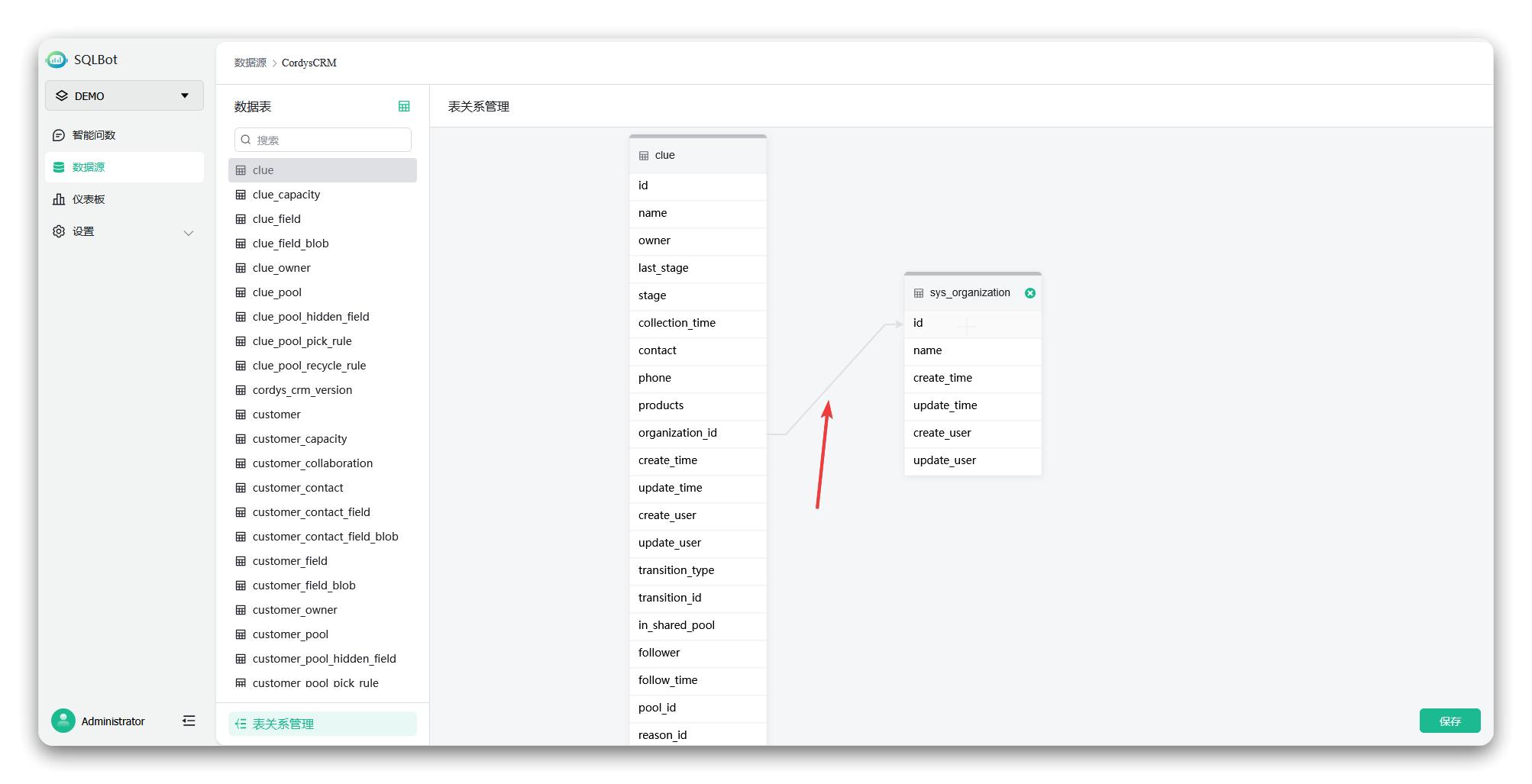 ▲图5 表关联关系设置
▲图5 表关联关系设置
第三步:提供标准示例(示例SQL)
对于具有固定统计口径或者复杂逻辑的业务查询(例如转化率、复杂的同比/环比分析、特定指标的计算等),仅依赖大语言模型的泛化能力,难以保证100%的问数准确性。SQLBot提供了示例SQL功能,就是针对复杂或高频问题提供一个标准答案库,供大语言模型进行学习和复用。
示例SQL的设置方法如下:
1. 识别复杂查询:提前收集业务人员经常询问,且需要使用复杂SQL实现的问题。比如在CordysCRM数据源中询问频率较高的“今年第三季度东区制造业赢单总数”问题,此问题涉及行业筛选和部门递归查询,需要将东区下级各部门中所有销售人员的赢单总数汇总为该下级部门的赢单总数,再进一步将东区所有下级部门的赢单总数汇总为“东区”这个上级部门的赢单总数;
2. 准备标准SQL:针对提前收集好的提问,编写一个逻辑正确、高性能的SQL答案。例如“今年第三季度东区制造业赢单总数”问题,涉及的SQL如下:
WITH RECURSIVE DepartmentHierarchy AS (
-- 锚点成员: 找出 '东区' 部门本身
SELECT
id
FROM
sys_department
WHERE
name = '东区'
UNION ALL
-- 递归成员: 找出所有下级部门
SELECT
id
FROM
sys_department d
INNER JOIN
DepartmentHierarchy dh ON d.parent_id = dh.id -- 递归查找所有子部门
)
SELECT
COUNT(t1.id) AS total_success_orders_q3 -- 统计符合条件的赢单总数
FROM
opportunity t1
JOIN
sys_organization_user t4 ON t1.owner = t4.user_id -- 关联商机负责人到组织成员 (获取部门ID)
JOIN
customer t2 ON t1.customer_id = t2.id -- 关联客户表
JOIN
customer_field t3 ON t2.id = t3.resource_id -- 联接客户自定义属性表
WHERE
t1.stage = 'SUCCESS' -- 筛选赢单阶段
-- **部门范围过滤:**
AND t4.department_id IN (SELECT id FROM DepartmentHierarchy)
-- **行业过滤 (自定义属性,使用模糊匹配):**
AND t3.field_id = '1751888184000005' -- 行业字段 ID
AND t3.field_value LIKE '%制造%' -- 筛选行业值中包含 '制造' 关键词的客户
-- **时间范围过滤:当前年份的第三季度 (7月1日到9月30日)**
AND FROM_UNIXTIME(t1.expected_end_time / 1000) >= STR_TO_DATE(CONCAT(YEAR(CURDATE()), '-07-01 00:00:00'), '%Y-%m-%d %H:%i:%s')
AND FROM_UNIXTIME(t1.expected_end_time / 1000) <= STR_TO_DATE(CONCAT(YEAR(CURDATE()), '-09-30 23:59:59'), '%Y-%m-%d %H:%i:%s');3. 录入示例SQL:
① 问题概述:输入用户可能使用的自然语言问题,例如“今年第三季度东区制造业赢单总数”或“东区今年第三季度赢单中,属于制造业的订单总数是多少”;
② 示例SQL:粘贴准备好的对应的标准SQL语句。
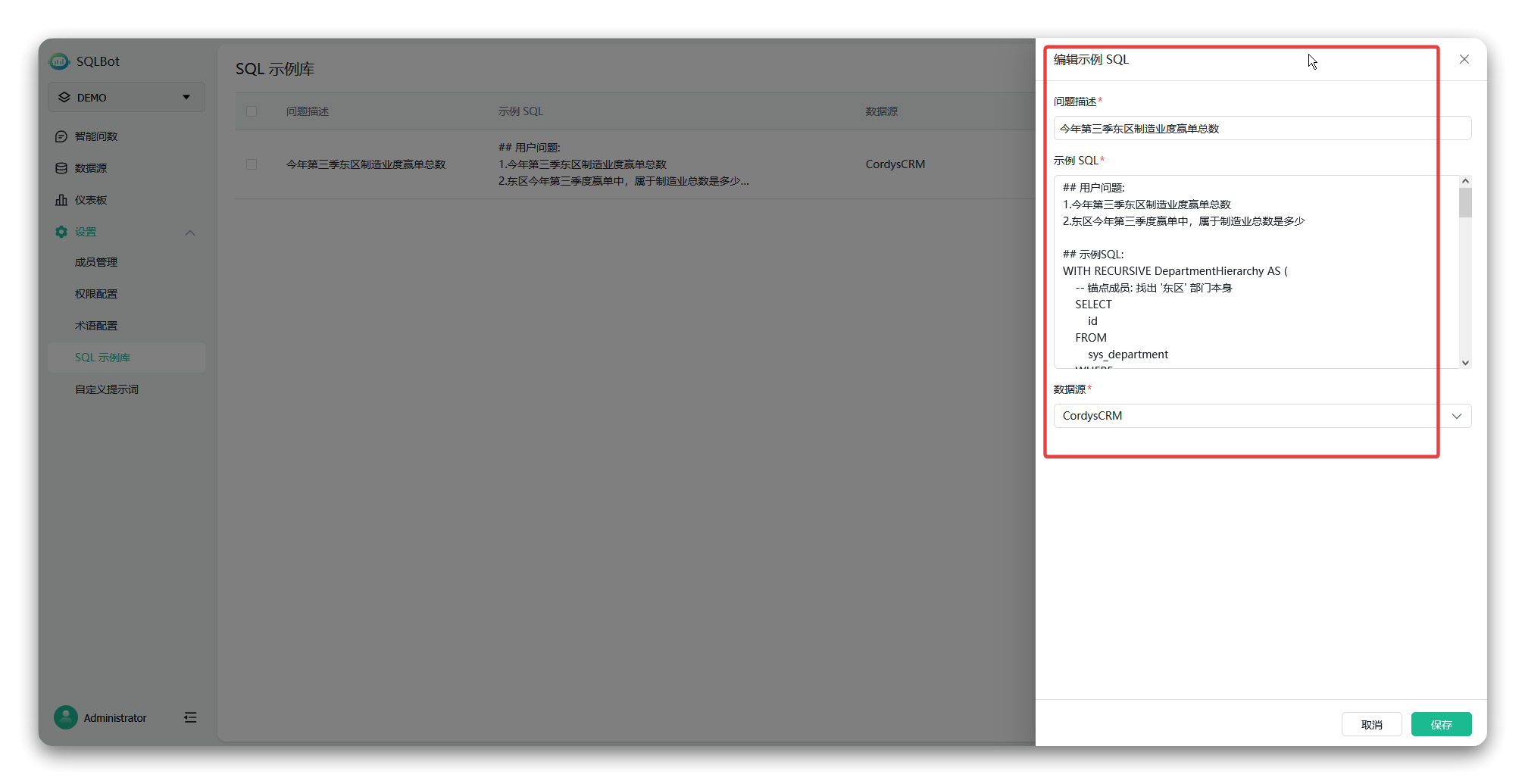 ▲图6 示例SQL编辑界面
▲图6 示例SQL编辑界面
第四步:消除指标歧义(自定义术语)
业务人员在日常沟通中习惯使用大量缩写或专有术语,这些口语化或业务化的叫法往往与数据库中专业的、甚至由计算表达式定义的字段名称不一致。自定义术语功能,用于建立业务人员的口语叫法与数据库中标准字段或计算表达式之间的映射词典。自定义数据的设置方法如下:
1. 进入“自定义术语”管理界面;
2. 添加术语(以飞致云产品线为例,不同的产品有不同的简称):
■ 术语名称:输入“MK/JS/CE/JMS/DE/MS”;
■ 术语描述:用于详细解释术语在数据库的查询逻辑。例如:“如果用户问题中采用了产品简称(MK=MaxKB,CloudExplorer=CE=云管,JS=JMS=JumpServer,DE=DataEase,MS=MeterSphere),在编写SQL时需要将简称转化为产品全称。”
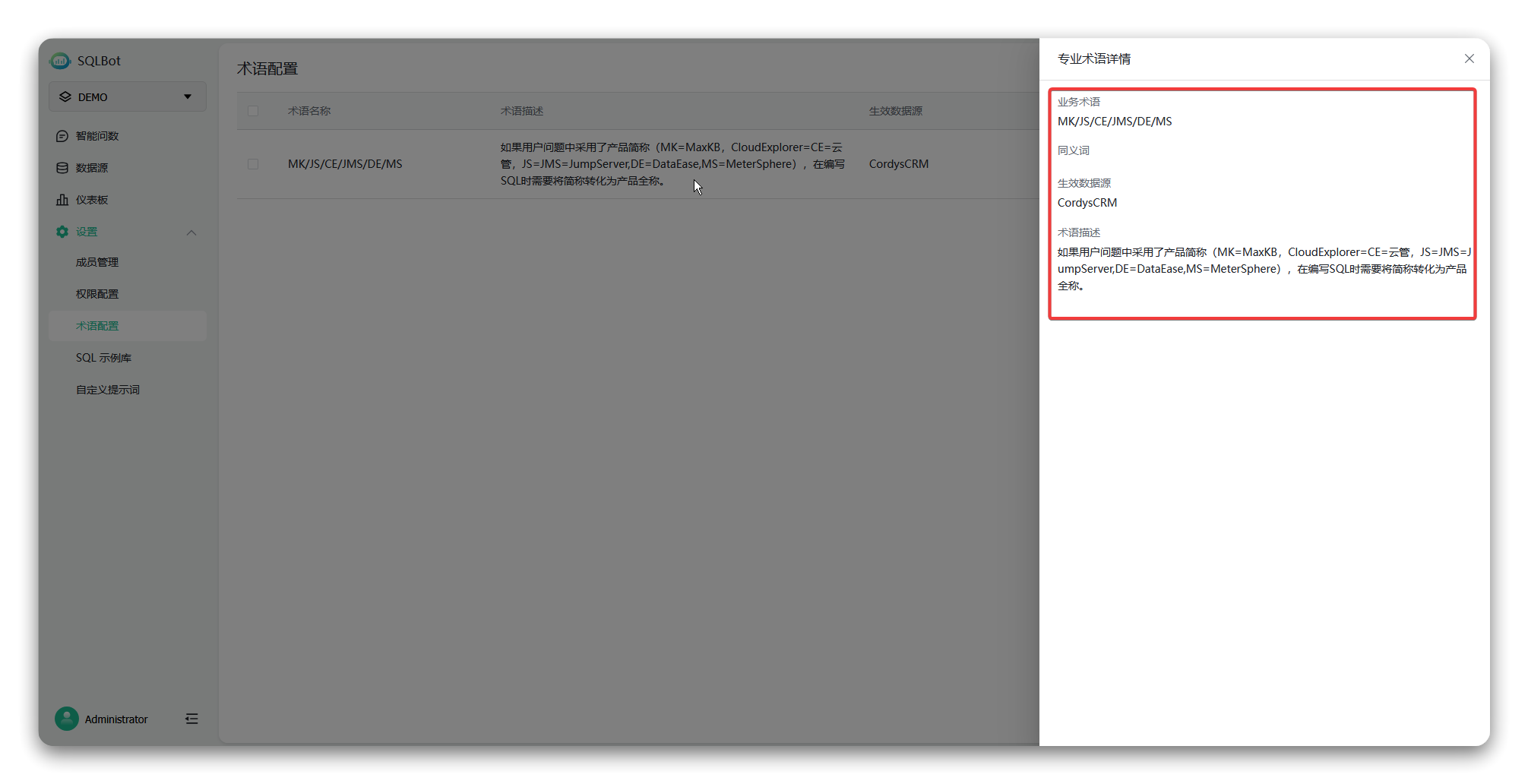 ▲图7 自定义术语编辑界面
▲图7 自定义术语编辑界面
三、总结
提升SQLBot智能问数的准确性,是一个系统性配置业务上下文的过程。我们在使用SQL开源智能问数系统时,通过表管理、表关联关系管理、示例SQL、自定义术语这四个步骤,可以很好地配置业务上下文,大幅提高大语言模型生成业务查询SQL语句的准确率。
 ▲图8 SQLBot智能问数结果示例
▲图8 SQLBot智能问数结果示例