
MaxKB开源企业级智能体平台的高级编排中提供了文档内容提取组件,其主要输出的是Markerdown格式的文本内容。然而,当文档内嵌架构图、流程图、图表等图片信息时,这些视觉内容就无法被有效提取,导致后续大语言模型(LLM)在回答时可能会遗漏关键信息,影响问答的准确性与完整性。
本文为您介绍MaxKB图文混合文档分析工作流的搭建方案。该方案旨在利用MaxKB的高级编排功能,通过自定义函数和图片理解节点,构建一个能够将文档文本内容和图片视觉解析结果进行融合分析的工作流,实现对图文混合文档的深度理解。
一、 实现方案
图文混合文档分析工作流的核心是实现文本内容中的图片提取和循环处理。整体流程说明如下:
1. 文档提取:通过MaxKB的文档内容提取节点,将用户上传的文档内容提取为Markdown格式文本,并保存为会话变量。
2. 动态图片处理函数:编写Python函数,接收Markdown文本,并执行以下逻辑:
① 从Markdown格式文本中解析出图片链接或标识;
② 将解析出的图片信息转换为MaxKB图片理解节点和图片位置提取节点所需的JSON数组结构。
3. 将数组内容倒序输出:为避免正序插入导致图片混乱,将数组倒序输出,为后续在Markdown文本中插入图片做好准备。
4. 循环与图片解析及插入文本:如果函数识别到图片,则进入循环结构,依次执行以下操作:
① 调用图片理解节点,返回图片内容的文本描述;
② 调用提取图片位置信息节点,返回图片在Markdown文本中的位置信息;
③ 编写Python函数,将Markdown文本会话变量、图片理解结果和提取图片位置信息结果传入,实现图片插入文本原位置。
5. LLM分析:调用大语言模型(LLM)分析节点,以融合后的图文上下文作为输入,执行用户定义的分析或其他任务。
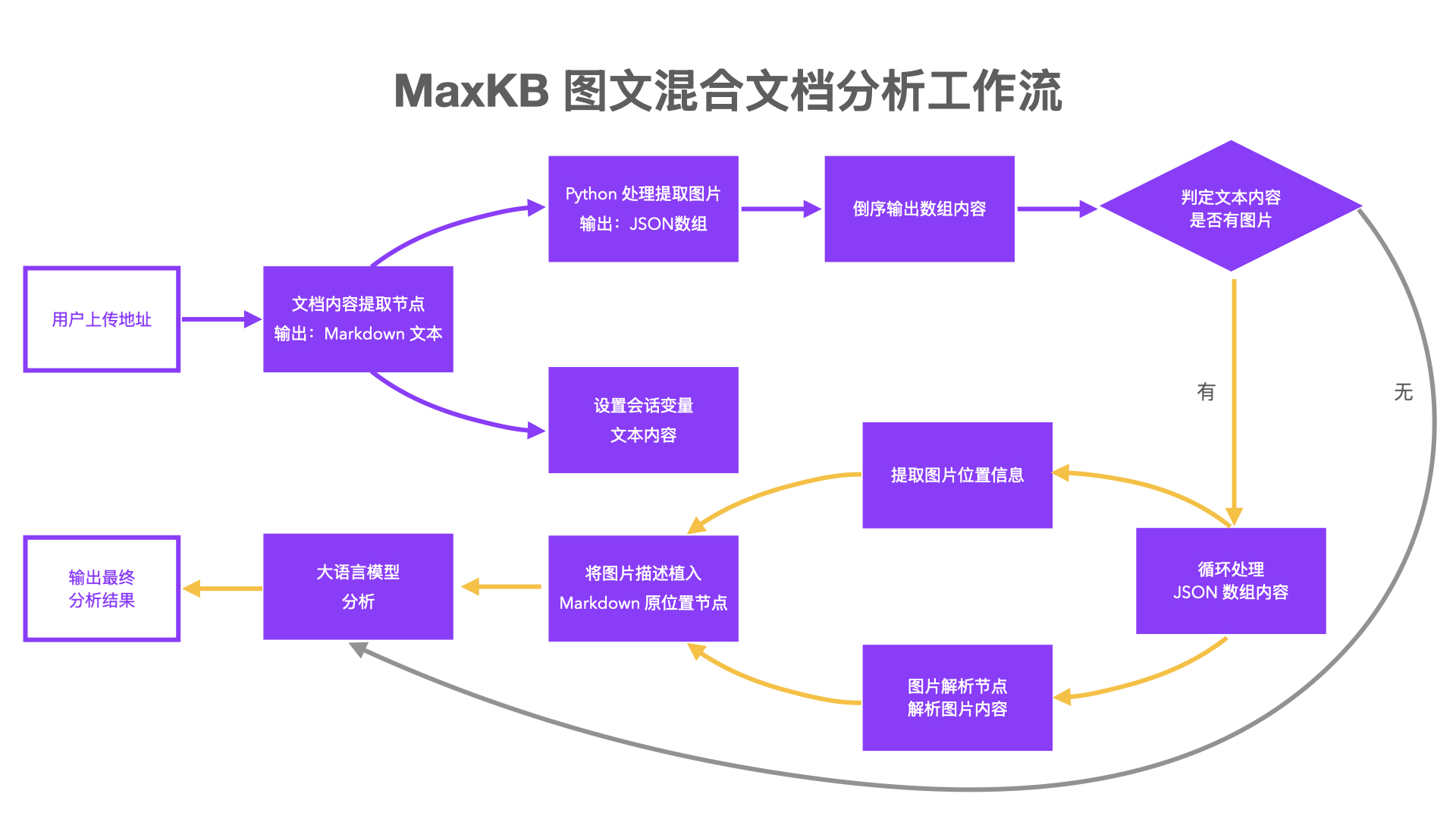
▲图1 MaxKB图文混合文档分析工作流流程图
二、高级编排和组件
本工作流由多个编排节点与自定义函数组成,以实现从文档解析到图文融合的完整链路。各节点的输入、输出与功能说明如下表所示:
表1 MaxKB图文混合文档分析工作流节点说
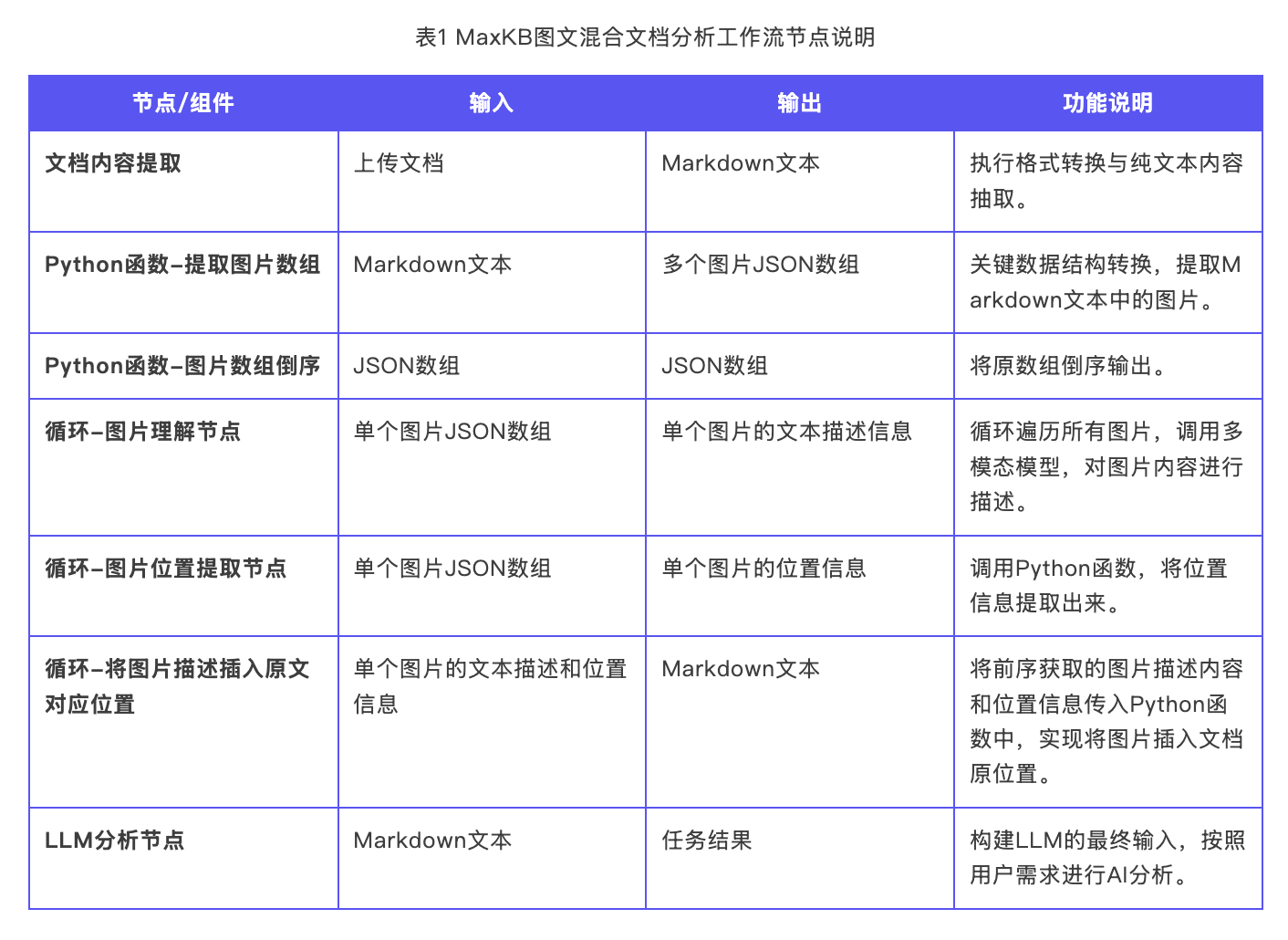
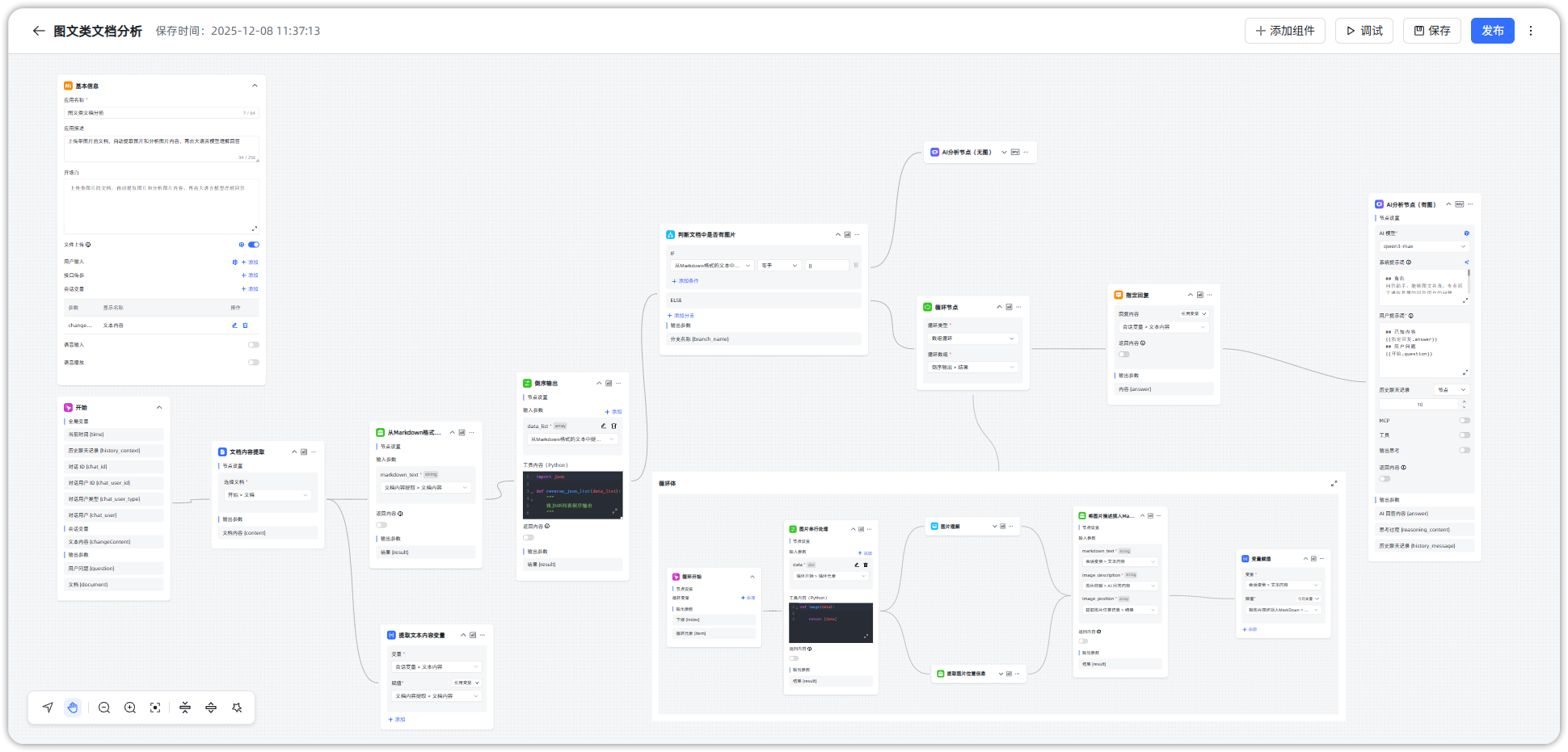
▲图2 MaxKB图文混合文档分析工作流
三、 核心函数工具
为实现工作流中的关键步骤,需要编写以下两个核心Python函数,分别用于提取图片信息和将图片描述插回原文。
1. 图片提取函数
在文档内容提取节点后,需调用函数从Markdown文本中解析出所有图片信息。具体代码如下:
#coding=utf-8
import re
import time
from typing import List, Dict, Any
def extract_images_from_markdown(markdown_text: str) -> List[Dict[str, Any]]:
"""
从Markdown格式的文本中提取所有图片引用,并返回格式化的图片信息数组,包括位置信息。
参数:
markdown_text (str): Markdown格式的文本内容
返回:
List[Dict[str, Any]]: 包含图片信息的字典数组,每个字典包含以下字段:
- name: 文件名
- percentage: 上传百分比(默认0)
- status: 状态(默认'ready')
- size: 文件大小(默认0)
- raw: 包含uid的字典
- uid: 唯一标识符
- url: 图片URL
- file_id: 文件ID(如果URL包含'./oss/file/')
- start: 图片在文本中的起始位置(新增)
- end: 图片在文本中的结束位置(新增)
"""
# 使用正则表达式匹配Markdown中的图片引用格式:
image_pattern = r'!\[(.*?)\]\(([^)]+)\)'
# 存储提取的图片信息
images_info = []
# 使用finditer获取所有匹配项及其位置
for match in re.finditer(image_pattern, markdown_text):
alt_text = match.group(1) # 图片alt文本
url = match.group(2) # 图片URL
start = match.start() # 匹配起始位置
end = match.end() # 匹配结束位置
# 处理文件名提取逻辑
if '/' in url:
# 从URL路径中提取文件名
filename = url.split('/')[-1]
# 如果URL中的文件名没有扩展名,尝试从alt_text中获取
if '.' not in filename:
if alt_text and '.' in alt_text:
# 提取alt_text中的文件名部分
alt_filename_candidates = alt_text.split(' ')
for candidate in alt_filename_candidates:
if '.' in candidate:
filename = candidate
break
# 如果还是没有扩展名,使用默认扩展名
if '.' not in filename:
filename = f'{filename}.png'
else:
# 如果URL不包含路径,使用默认命名
if alt_text and '.' in alt_text:
alt_filename_candidates = alt_text.split(' ')
filename = None
for candidate in alt_filename_candidates:
if '.' in candidate:
filename = candidate
break
if filename is None:
filename = f'image_{start}.png' # 使用位置确保唯一性
else:
filename = f'image_{start}.png'
# 从URL中提取file_id(如果URL格式为'./oss/file/xxx')
file_id = ''
if './oss/file/' in url:
file_id = url.split('./oss/file/')[-1]
# 生成唯一标识符(结合时间戳和位置避免冲突)
uid = int(time.time() * 1000) + start
# 构建图片信息字典
image_info = {
'name': filename,
'percentage': 0,
'status': 'ready',
'size': 0,
'raw': {'uid': uid},
'uid': uid,
'url': url,
'file_id': file_id,
'start': start, # 新增:在文本中的起始位置
'end': end # 新增:在文本中的结束位置
}
# 验证所有必要字段都存在
required_fields = ['name', 'percentage', 'status', 'size', 'raw', 'uid',
'url', 'file_id', 'start', 'end']
for field in required_fields:
if field not in image_info:
print(f"警告: 图片信息缺少字段 {field}")
images_info.append(image_info)
return image
▲图3 图片提取函数配置参考
在图片提取后,调用图片列表倒序函数,将数组进行倒序重排,方便后续插入原文定位使用。具体代码如下:
import json
def reverse_json_list(data_list):
"""
将JSON列表倒序输出
"""
# 使用切片反转列表,返回新列表
reversed_list = data_list[::-1]
return reversed_list2. 将图片描述插入Markdown文本中
在循环处理完每张图片的描述与位置后,需要调用函数将描述文本插入Markdown原文的对应位置。具体代码如下:
from typing import List, Dict, Any
def insert_single_image_description(
markdown_text: str,
image_description: str,
image_position: List[Dict[str, Any]]
) -> str:
"""
在Markdown文本的指定位置插入图片描述内容
参数:
markdown_text: Markdown文本内容
image_description: 图片描述文本
image_position: 图片位置信息列表,包含start、end、uid等键的字典列表
返回:
插入图片描述后的新Markdown文本
"""
# 获取第一个位置字典
position_dict = image_position[0]
if not isinstance(position_dict, dict):
raise TypeError(f"列表中的元素应为字典类型,但得到 {type(position_dict).__name__}")
# 获取位置信息
start = position_dict.get("start")
end = position_dict.get("end")
# 获取当前位置的原始文本片段
original_snippet = markdown_text[start:end]
# 构建要插入的内容
insertion = f"\n\n{image_description}\n"
# 插入图片描述到指定位置
result = markdown_text[:end] + insertion + markdown_text[end:]
retur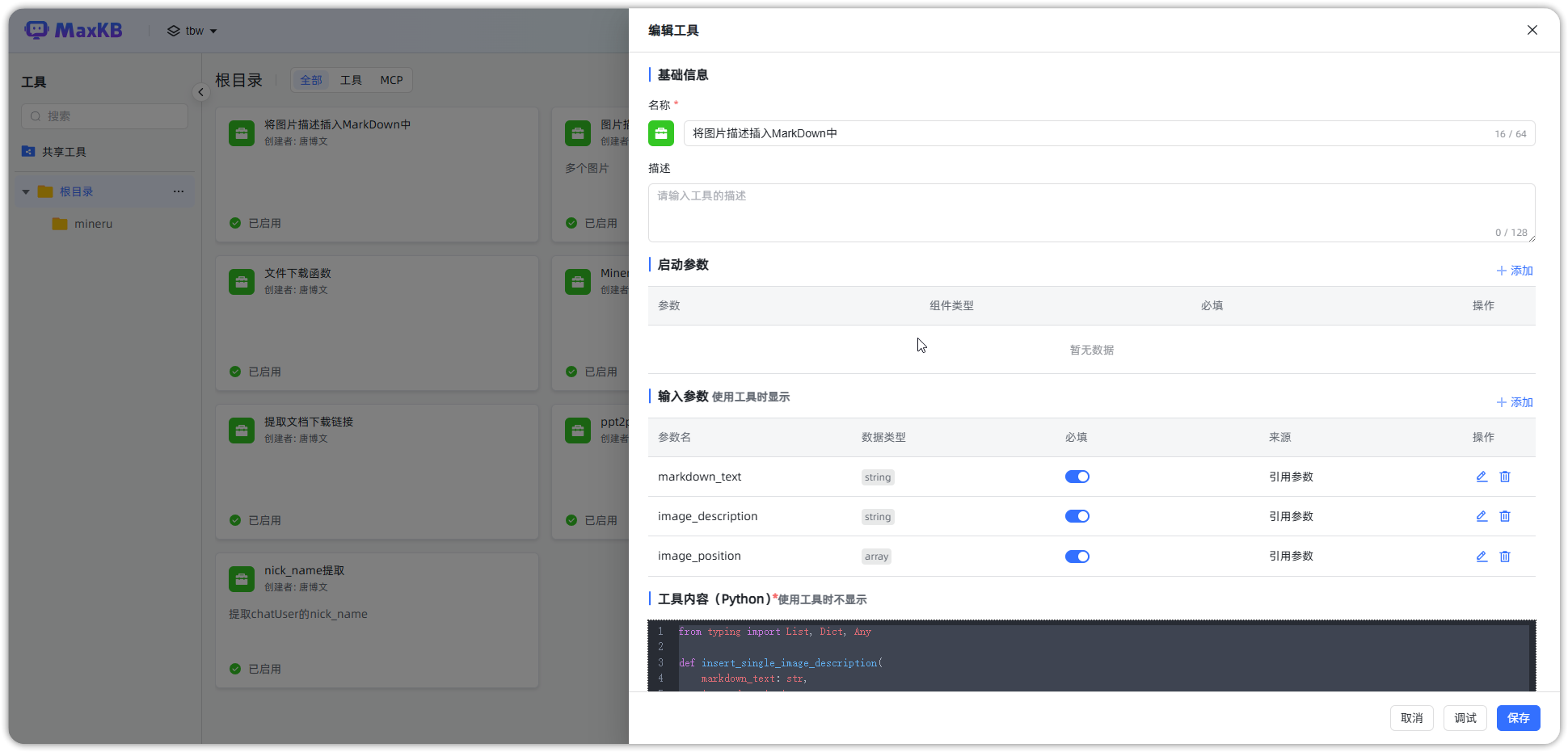
▲图4 图片描述插入原文函数配置参考
四、 效果展示和应用场景
在MaxKB图文混合文档分析工作流搭建完成后,我们来看下实现的具体效果。我们以包含多张分散图片的MaxKB产品介绍文档为例。例如,此文档中的“MaxKB的设计理念和RAG工作原理”完全采用图片进行表述,无文字内容说明:
▲图5 包含图片的示例文档
在MaxKB图文混合文档分析小助手的对话页面上传此文档,并提问“请理解文档内容”,大模型能够基于图文理解够给出准确回答。
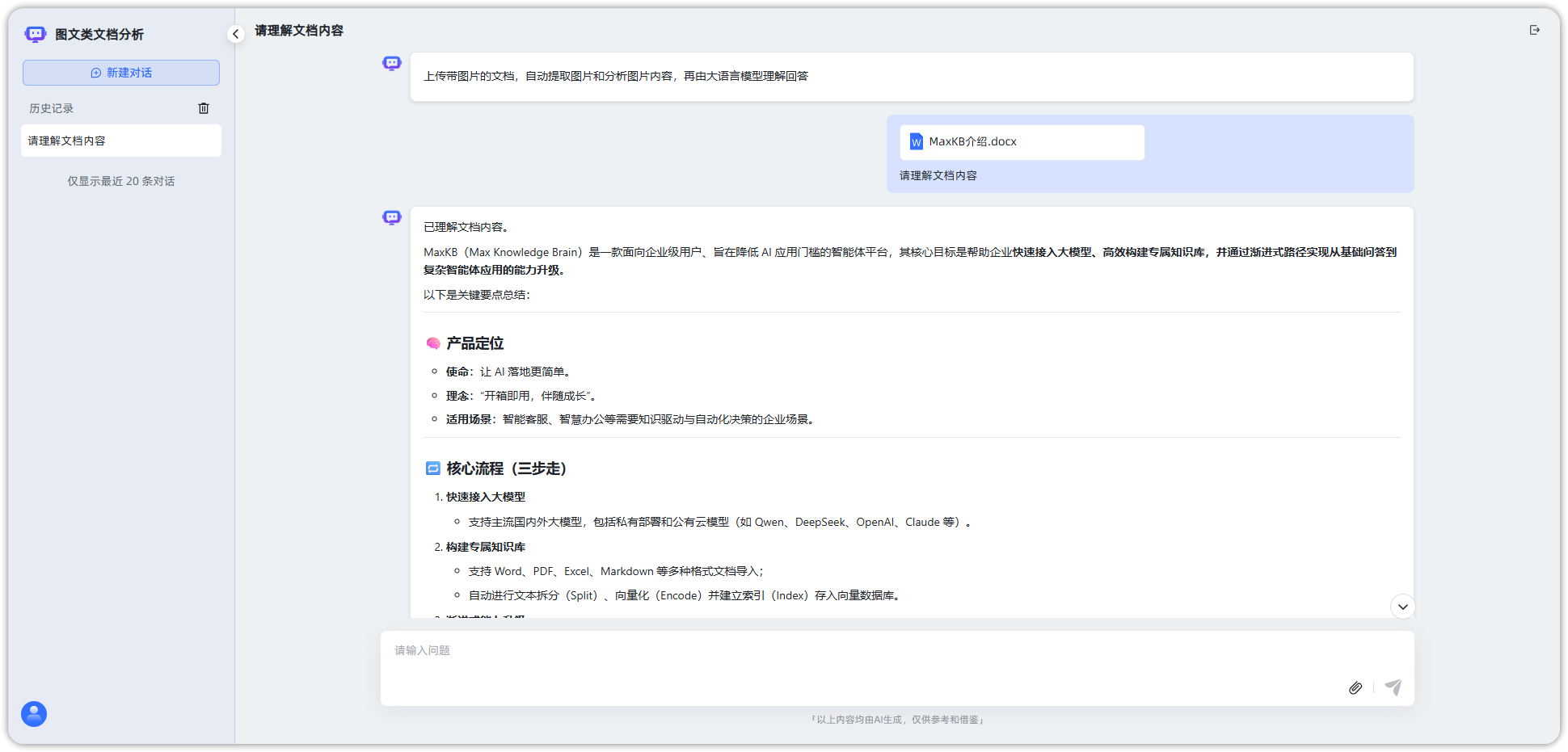
▲图6 图文混合文档分析小助手的问答效果
从执行过程可见,图文混合文档分析工作流利用图片理解节点对DOCX文档中的图片进行理解并输出文字描述,并且将图片插入了文档原位置。
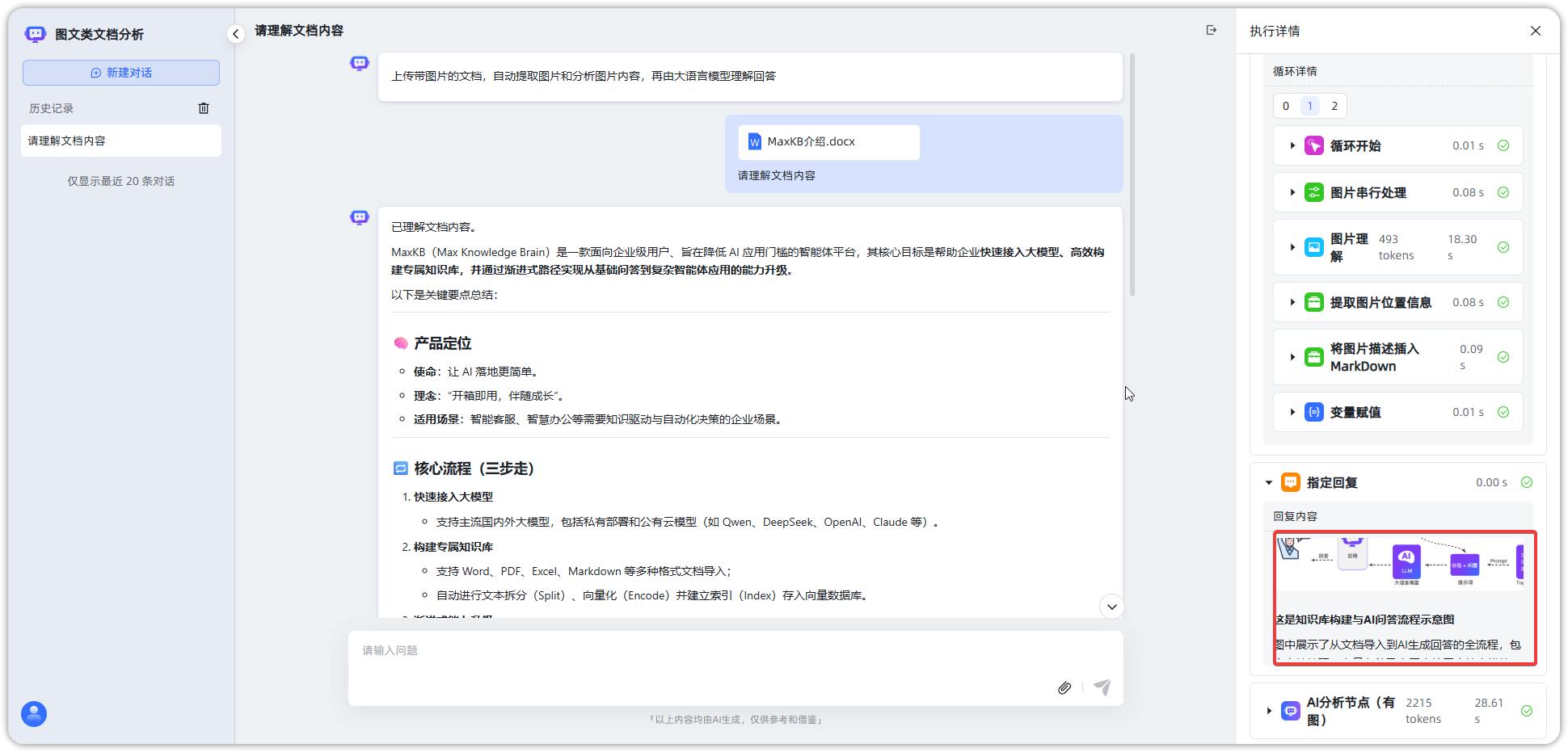
▲图7 图文混合文档分析小助手的执行过程
除此之外,图文混合文档分析工作流在MaxKB平台同样可以满足以下需要结合视觉和文字信息的复杂文档处理场景:
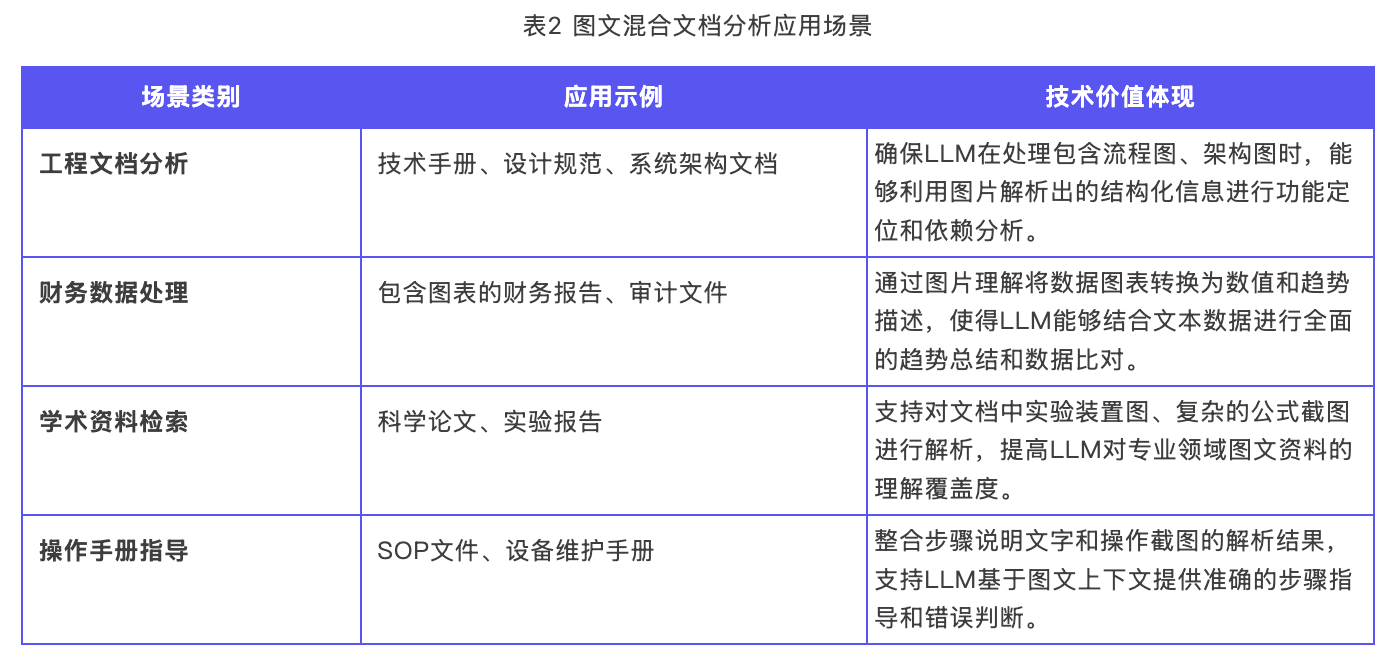
五、总结
本文为您介绍了MaxKB图文混合文档分析工作流通过“文本提取→图片提取→图片循环识别→多模态融合分析”的完整链路,实现对复杂图文混合文档的自动化、智能化处理过程。该方案不仅可以有效提升文档信息提取的完整性与准确性,更为大语言模型提供了强大的图文混合文档理解能力。
在实际的应用中,企业可以直接将该工作流应用在工程文档分析、财务数据处理、学术资料检索、操作手册指导等场景,可以有效增强MaxKB平台的智能问答与内容分析的覆盖度与准确性,降低多模态文档处理难度,帮助企业加速构建具备全面语义理解能力的AI应用。